Sprout API
Sprout API Overview
The Sprout API provides an externally accessible API for you to access your owned social profile data so you can use that data to power dashboards and automate your reporting.
By developing or accessing these endpoints, you are acknowledging that you have read and agreed to the developer terms. If you are interested in being a tech partner with Sprout, please fill out this form so we can get in touch.
Available Data Overview
✅ The Sprout API includes:
- ✅ Owned Profile Data - This matches the data available in Sprout’s Profile Performance, X Profiles, Facebook Pages, Instagram Business Profiles, LinkedIn Pages, Pinterest Profiles, TikTok Profiles and YouTube Videos Report.
- ✅ Post Data - This matches the data available in Sprout’s Post Performance Report.
- ✅ Owned demographic data - View the data available in Sprout’s Facebook Pages, Instagram Business Profiles, LinkedIn Pages, and TikTok Profiles Report
- ✅ Message Data - Get detailed information, including metadata, about your messages. This includes messages received by and replied to from your profiles.
- ✅ Publishing Posts - Create Publishing Posts within Sprout.
- ✅ Media Upload - Upload Media for use with Publishing Posts.
- ✅ Direct Tableau Connector - Easily analyze Sprout API data directly in Tableau. For more details reference the Tableau Connector section of this doc.
- ✅ Listening Topics - Retrieve earned media related metrics and messages found within your Listening Topics. For more details reference sections regarding Topics within this doc.
- ✅ Cases Data - Get detailed information about your cases.
For specific data and metrics, reference the Metrics and Fields sections of this doc.
🚫 The Sprout API does not currently include:
- 🚫 Paid (Ad Account) data
- 🚫 Listening data from X
- 🚫 Listening message-level data from Reddit
Terminology
- Post: A post refers to a message that was published by an owned profile. A Publishing Post exists in Sprout and is intended to be published at a future time.
- Message: A message refers to any message that was published by or received by an owned profile or Topic. All posts are messages, but not all messages are posts.
- Profile: A profile refers to an account, page, handle, etc. on a native social network, like X or Instagram.
- Case: A case refers to a customer inquiry, issue, or other engagement that may require action by a social care agent. Cases can have one or many messages associated with it.
Accessing the APIs
Pre-requisites
- Plan: Your account needs to be on the appropriate plan which enables API access. If you are unsure, please contact your sales representative or contact support.
- Permissions: Users need to have the API Permissions permission in order to manage the configurations for API access. If you are unsure, please contact your sales representative or contact support.
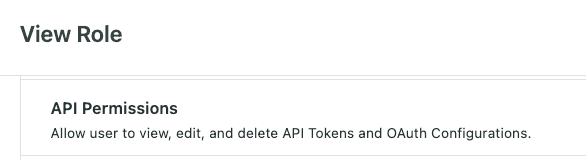
- Terms of Service: If you haven't already done so, accept Sprout’s Analytics API Terms of Service. To do so,
- Log in to Sprout
- Navigate to the Settings > Global Features > API Page.
- Accept Sprout’s Analytics API Terms of Service.
Once you have completed the pre-requisites, Sprout supports 2 ways to make authenticated API requests:
-
Using OAuth 2.0 (Recommended)
Using OAuth 2.0
Sprout's API support OAuth 2.0 to access the API. With this method, Sprout will issue short lived credentials i.e. JSON Web Token (JWT) access tokens, which should be used to authenticate with Sprout's APIs.
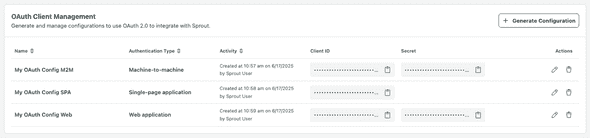
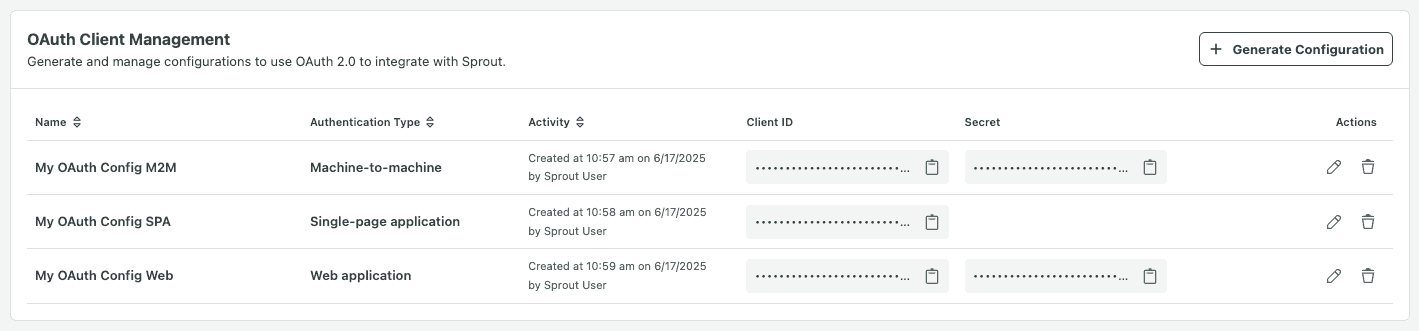
OAuth Client Management
To view & manage OAuth client configurations,
-
Log in to Sprout
-
Navigate to the Settings > Global Features > API Page.
-
Navigate to OAuth Client Management section.
-
Here you will be able to view and manage previously created OAuth client configurations.
Creating OAuth Client Configuration
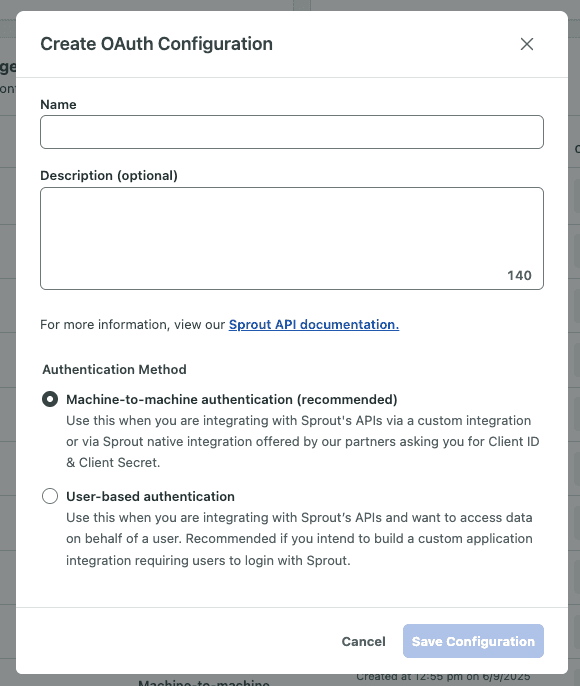
Sprout supports the following authentication methods,
-
Machine-to-machine authentication (recommended): Use this when you are integrating with Sprout's APIs via a custom integration or via Sprout native integration offered by our partners asking you for Client ID & Client Secret.
-
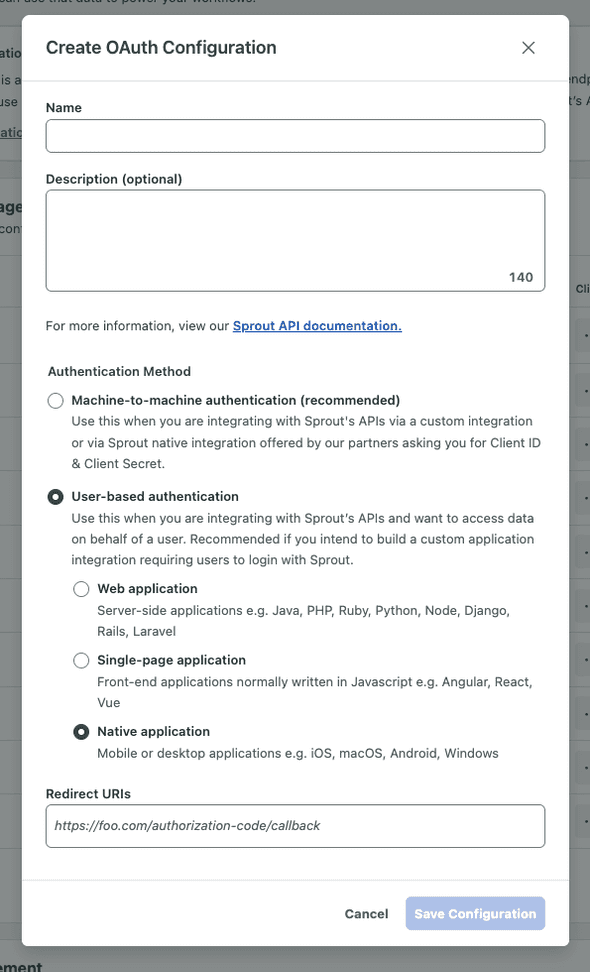
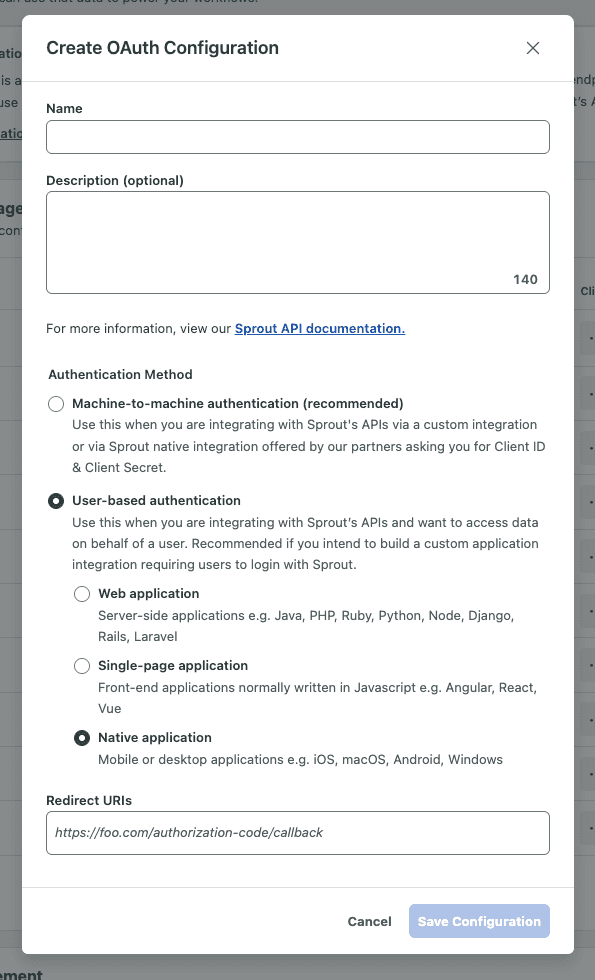
User-based authentication: Use this when you are integrating with Sprout’s APIs and want to access data on behalf of a user. Recommended if you intend to build a custom application integration requiring users to login with Sprout.
To create a new OAuth client configuration,
-
Log in to Sprout
-
Navigate to the Settings > Global Features > API Page.
-
Navigate to OAuth Client Management section.
-
Click Generate configuration in the upper right corner.
-
Select the authentication method e.g. Machine-to-machine authentication
-
Enter the name for your client along with a description.
-
(Optionally) If you selected User-based authentication, you will need to provide the list of allowed redirect URIs.
-
Save the configuration!
-
Retrieve the client id and secret, by navigating the OAuth Client Management section and copy the client id and secret. Be sure to store these securely!
Obtaining JSON Web Token (JWT) Access Token
To obtain JSON Web Token (JWT) access token from Sprout, you will integrate with Sprout's Authorization Server
- Authorization Server URL: https://identity.sproutsocial.com/oauth2/84e39c75-d770-45d9-90a9-7b79e3037d2c/.well-known/oauth-authorization-server
For machine-to-machine authentication method, to retrive a token, you will use the client id & secret and make a call to the token api e.g.
curl --location 'https://identity.sproutsocial.com/oauth2/84e39c75-d770-45d9-90a9-7b79e3037d2c/v1/token' \
--header 'Content-Type: application/x-www-form-urlencoded' \
--data-urlencode 'client_id=<paste_your_client_id_here>' \
--data-urlencode 'client_secret=<paste_your_client_secret_here>' \
--data-urlencode 'grant_type=client_credentials' \
--data-urlencode 'scope=organization_id'
For user-based authentication, you will use the,
- OAuth client configuration that you generated in the previous step
- Authorization Endpoint & Token Endpoint listed on the Authorization Server
- Integrate into your custom application requiring users to login with Sprout.
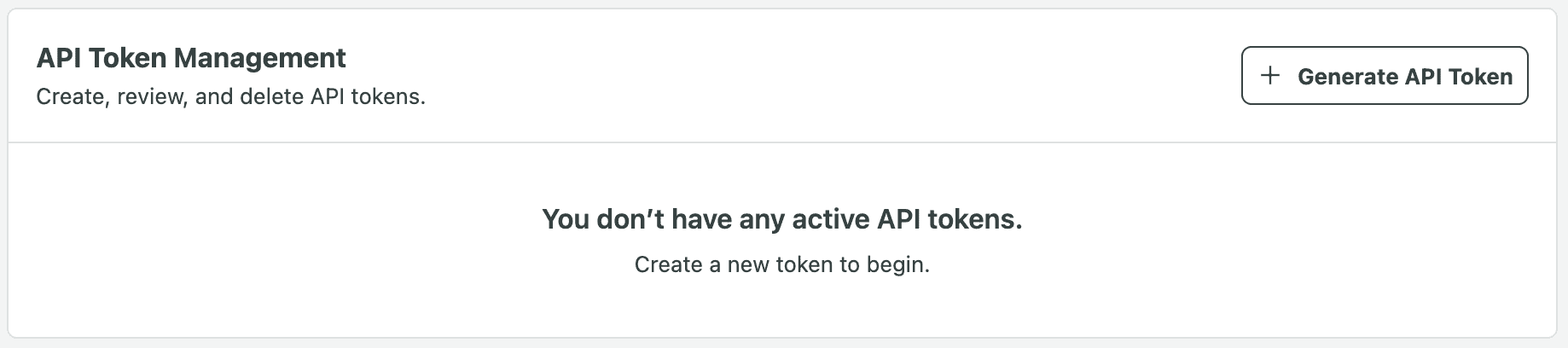
Using API Tokens
Any user with the API Permissions permission can create new API tokens via the API Tokens settings page. They can also view or invalidate existing tokens (i.e. prevent the tokens from being used for client requests).
-
Log in to Sprout
-
Navigate to the Settings > Global Features > API Page.
-
Click Generate API Token in the API Token Management section.
- Enter a name for your token.
- Copy the token for use. Be sure to store these securely!
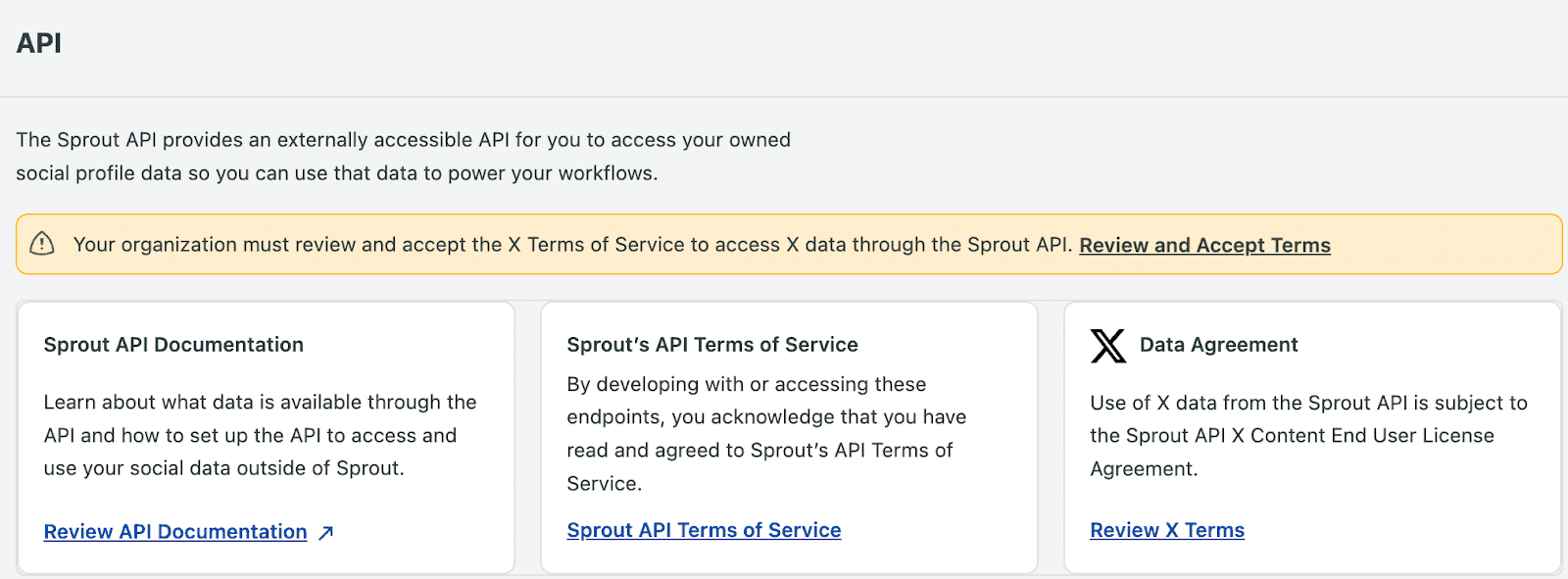
X Data: X Content End User License Agreement
Note: X has additional compliance requirements around exposing data through the API. You’re required to review and accept the Sprout API X Content End User License Agreement before you can access X's data through the Sprout API.
Unless X does not approve your specific use case, any Sprout user with the API Permissions permission will need to accept the Sprout API X Content End User License Agreement to access X’s data. This appears at the top of the API page under Global Features in Settings.
Sprout API Details
API URL
https://api.sproutsocial.com
Endpoints Overview
Sprout API endpoints are grouped into three collections:
- Customer Metadata Endpoints - Use these endpoints to obtain high-level information about your Sprout customer account and profiles you have access to; many of these endpoints provide data needed to make requests to other Sprout API endpoints.
- Analytics Endpoints - These endpoints provide information about your Sprout profiles, and posts.
- Listening Endpoints - These endpoints provide metrics and messages related to your Listening Topics.
- Messages Endpoint - This endpoint provides detailed data and metadata about your Sprout messages.
- Publishing Post Endpoints - These endpoints allow for creation and management of posts that will be published at a future time.
- Media Endpoints - These endpoints are used to upload media for use within the API.
- Cases Endpoint - These endpoints provide detailed data about your Sprout cases.
| Customer Metadata Endpoints | Description |
|---|---|
GET /v1/metadata/client |
Customer IDs and Names |
GET /v1/<customer ID>/metadata/customer |
Customer Profiles |
GET /v1/<customer ID>/metadata/customer/tags |
Customer Tags |
GET /v1/<customer ID>/metadata/customer/groups |
Customer Groups |
GET /v1/<customer ID>/metadata/customer/users |
Customer Users |
GET /v1/<customer ID>/metadata/customer/topics |
Customer Topics |
GET /v1/<customer ID>/metadata/customer/teams |
Customer Teams |
GET /v1/<customer ID>/metadata/customer/queues |
Customer Case Queues |
| Analytics Endpoints | Description |
|---|---|
POST /v1/<customer ID>/analytics/profiles |
Owned Profile Analytics |
POST /v1/<customer ID>/analytics/posts |
Post Analytics |
| Listening Endpoints | Description |
|---|---|
POST /v1/<customer ID>/listening/topics/<topic id>/messages |
Topic Messages |
POST /v1/<customer ID>/listening/topics/<topic id>/metrics |
Topic Metrics |
| Messages Endpoint | Description |
|---|---|
POST /v1/<customer ID>/messages |
Inbox Messages |
| Publishing Post Endpoints | Description |
|---|---|
POST /v1/<customer ID>/publishing/posts |
Create Publishing Post |
GET /v1/<customer ID>/publishing/posts/<publishing_post_id> |
Retrieve Publishing Post |
| Media Upload Endpoints | Description |
|---|---|
POST /v1/<customer ID>/media/ |
Upload Media in a single request < 50MB |
POST /v1/<customer ID>/media/submission |
Start multipart media upload |
POST /v1/<customer ID>/media/submission/<submission_id>/part/<part_number> |
Continue multipart media upload |
GET /v1/<customer ID>/media/submission/<submission_id> |
Complete multipart media upload |
| Cases Endpoints | Description |
|---|---|
POST /v1/<customer ID>/cases/filter |
Retrieve Cases |
General API Structure
All endpoints use the following naming structure:
/<version>/<customer ID>/<endpoint path>
Where:
- version is the API major version number
- customer ID is your Sprout customer ID
Versioning
The Sprout API is versioned using a MAJOR.MINOR version format.
You can specify only the major number in requests, but the full version is included in responses.
A major version represents a breaking change to the API, including updates to the syntax and semantics for making requests of the APIs and the syntax and semantics of the response of the API.
A minor version represents a backwards compatible change to the API, such as adding new metrics, new endpoints, metric updates, etc. Minor versions are reflected in documentation, but not the API URL itself. Due to the backwards compatibility of minor versions, you only need to specify the major version in the URL path.
Rate Limits
You’re limited to the following number of requests:
- 60 requests per minute
- 250,000 requests per month
Endpoints
Requests
All requests have the following format:
Request Headers
| Type | Value |
|---|---|
| Authorization | Bearer <OAuth access token OR API token> |
| Accept | application/json |
| Content-Type | application/json |
Note that the Authorization header accepts both account-scoped and OAuth access tokens.
Request Body
The content body for all requests are JSON objects. Details of the structure of that JSON object depend on the endpoint.
Responses
HTTP Status Codes
The following HTTP status codes returned with the response have the following meanings:
| Code | Meaning | Corrective Action |
|---|---|---|
| 200 OK | Request was processed successfully. | None. You should be able to access the result of the request in the response body. |
| 202 Ready | Request was processed successfully but not ready for a proper answer. | Retry the request. If this code persists, contact support. |
| 400 Bad Request | The request is malformed and does not conform with the request bodies specified in this document. | Update the request body. |
| 401 Unauthorized | The request does not contain a valid access token or that access token has expired. | Reauthenticate and obtain a fresh token. |
| 403 Forbidden | The request is accessing customer or profile data that the client is not allowed access to. | Update the request body. |
| 404 Not Found | The client is requesting an endpoint that does not exist. | Check your endpoint, and use an existing endpoint. |
| 405 Method Not Allowed | The client is using an HTTP verb that is not appropriate. | Use the HTTP verb listed for the API endpoint you’re using, typically POST or GET. See the specific endpoint documentation for details. |
| 415 Unsupported Media Type | The client has submitted a request body that is not JSON or is requesting a response that is not JSON | Correct the Accept and Content-Type headers to use JSON. |
| 429 Too Many Requests | The client is making requests too quickly or has exhausted the allowed requests in a month. | Slow down your requests. |
| 500 Internal Server Error | The server had an issue processing the request. | Retry the request. If this code persists, contact support. |
| 503 Service Unavailable | The server is overloaded and cannot process the request. | Retry the request. If this code persists, contact support. |
| 504 Gateway Timeout | The server was unable to produce a result in time. | Retry the request. If this code persists, contact support or decrease the scope of the request (smaller date ranges, less profiles, etc.). |
Response Headers
The following headers are returned with each response:
| Header | Description | Sample Value |
|---|---|---|
| X-Sprout-Request-ID | Randomly generated UUID to trace a client request and response. Returned to you for debugging. | bedc387d-9b99-42ae-9887-cc15f9885d47 |
| X-Sprout-API-Version | Major and minor version of the response | 1.1 |
| X-Sprout-Server-Version | Server version, including the major, minor, and build number. The major and minor version reflect the latest available version of the API. | 1.1.3018 |
Response Body
Responses from the data API are JSON objects with the following format:
| Key | Value |
|---|---|
data |
JSON array containing the results of the API request (JSON objects for each message, dimensioned data, etc.) |
paging |
Optional JSON object describing the status of paging the data returned in the response. |
error |
Optional JSON string containing an error message in the event there is an issue with the request. |
Customer Metadata Endpoints
Customer Metadata endpoints are all HTTP GET endpoints. Use these to obtain information about the customer and profiles you have access to.
Client (Customer ID) Endpoint
GET /v1/metadata/client
This endpoint is used to obtain the customer IDs and names you have access to.
Request Body - Client (Customer ID) Endpoint
No request body is necessary for this request.
Response Data - Client (Customer ID) Endpoint
The data array contains JSON objects of customer IDs and names you have access to. For example:
{
"data": [
{"customer_id": 687751, "name": "My Business"}
]
}
Customer Profiles Endpoint
GET /v1/<customer ID>/metadata/customer
This endpoint is used to obtain the list of customer profile IDs you have access to.
Request Body - Customer Profiles Endpoint
No request body is necessary for this request.
Response Data - Customer Profiles Endpoint
The data array contains an array of JSON objects describing the social network profiles that are available to that client. The JSON object contains:
| Key | Description | Example Value |
|---|---|---|
customer_profile_id |
The customer profile ID used by Sprout to identify this social network profile. | 492 |
network_type |
The type of social network (X, Facebook, Instagram, etc.) | twitter |
name |
The human-facing name of the social network profile | Sprout Social |
native_name |
The user name, screen name, page URL, etc. the social network uses to identify a unique profile. | sproutsocial |
native_id |
The ID used by the social network to identify a unique profile. | 42793960 |
groups |
An array of group IDs this profile belongs to. | [23598, 65245] |
network_metadata |
(Optional) Additional metadata fields only available for a subset of profile types. address available for Google My Business, Yelp, Tripadvisor. store_code available for Google My Business and Facebook locations. |
An example response:
{
"data": [
{
"customer_profile_id": 492,
"network_type": "twitter",
"name": "Sprout Social",
"native_name": "sproutsocial",
"native_id": "42793960",
"groups": [23598, 65245]
},
{
"customer_profile_id": 6810812,
"network_type": "google_my_business",
"name": "Store Location",
"native_name": null,
"native_id": "13955863841611236869",
"groups": [2449295],
"network_metadata": {
"store_code": "872-P",
"address": "1308 Centerville Rd, Wilmington, DE, 19808",
}
},
...
]
}
Customer Tags Endpoint
GET /v1/<customer ID>/metadata/customer/tags
This endpoint is used to obtain the list of message tags you created in Sprout. The response includes all active and archived tags, regardless of when the tag was created. Previously deleted tags are permanently removed from Sprout and are not included.
Request Body - Customer Tags Endpoint
No request body is necessary for this request.
Response Data - Customer Tags Endpoint
The data array contains an array of JSON objects describing the tags that are available. This includes all tags in a single response. There is no limit or pagination in the response. The JSON object contains:
| Key | Description | Example Value |
|---|---|---|
tag_id |
The ID used by Sprout to identify this message tag | 321 |
any_group |
Whether or not this tag is available in any customer group | false |
active |
Whether this tag is active (or archived) in Sprout Social | true |
text |
The text of the tag | "Social Support" |
type |
The type of the tag (LABEL or CAMPAIGN) |
"LABEL" |
groups |
An array of the IDs of the groups this tag is available in | [206063] |
An example response:
{
"data": [
{
"tag_id": 321,
"any_group": false,
"active": true,
"text": "Social Support",
"type": "LABEL",
"groups": [206063]
},
...
]
}
Customer Groups Endpoint
GET /v1/<customer ID>/metadata/customer/groups
This endpoint is used to obtain the list of groups you created in Sprout.
Request Body - Customer Groups Endpoint
No request body is necessary for this request.
Response Data - Customer Groups Endpoint
The data array contains an array of JSON objects describing the groups that are available to you. The JSON object contains:
| Key | Description | Example Value |
|---|---|---|
group_id |
The ID used by Sprout to identify this group | 1234 |
name |
The name of the group | "Sprout Social Team" |
An example response:
{
"data": [
{
"group_id": 1234,
"name": "Sprout Social Team"
},
...
]
}
Customer Users Endpoint
GET /v1/<customer ID>/metadata/customer/users
This endpoint is used to obtain the list of users that are active for your customer.
Request Body - Customer Groups Endpoint
No request body is necessary for this request.
Response Data - Customer Groups Endpoint
The data array contains an array of JSON objects describing the active users for your customer. The JSON object contains:
| Key | Description | Example Value |
|---|---|---|
id |
The ID used by Sprout to identify this user | 1234 |
name |
The name of the user | "John Doe" |
email |
The email address of the user | "johndoe@example.com" |
An example response:
{
"data": [
{
"id": 1234,
"name": "John Doe",
"email": "johndoe@example.com"
},
...
]
}
Customer Topics Endpoint
GET /v1/<customer ID>/metadata/customer/topics
Utilize this endpoint to find all Topics associated with your customer id. Each Topic includes associated metadata such as themes and available date ranges.
Request Body - Customer Topics Endpoint
No request body is necessary for this request.
Response Data - Customer Topics Endpoint
The data array contains an array of JSON objects describing the Topics that are available to the client. The JSON object contains:
| Key | Description | Example Value |
|---|---|---|
id |
An identifier for the Topic used to make calls for Topic data | 81391723128379 |
name |
The name of the Topic | Sprout Social Brand |
topic_type |
The Topic category | BRAND_HEALTH |
description |
A description given by the user when creating the Topic | A Topic for the brand. |
group_id |
The group the Topic belongs to | 123456789 |
theme_groups |
The list of themes belonging to the Topic. Themes are always grouped even when they may not appear that way in app. | [{"name":"Complaints","themes":[{"id":"018085b6-1dc3-43eb-ab28-3c430c0d2412","name":"SlowLogin"}]}] |
theme_groups.name |
The name of the theme group | Complaints |
theme_groups.themes |
The themes that belong to the group | [{"id":"018085b6-1dc3-43eb-ab28-3c430c0d2412","name":"SlowLogin"}] |
theme_groups.themes.id |
The unique ID of the theme | 018085b6-1dc3-43eb-ab28-3c430c0d2412 |
theme_groups.themes.name |
The name for the theme | SlowLogin |
availability_time |
A date representing how far back data is available for the Topic | 2020-11-17T09:32:00Z |
An example response:
[
{
"id": "81391723128379",
"description": "",
"group_id": 1330748,
"theme_groups": [
{
"name": "Complaints",
"themes": [
{
"id": "018085b6-1dc3-43eb-ab28-3c430c0d2412",
"name": "Login Errors"
}
],
}
],
"availability_time": 1600895454244,
"topic_type": "INDUSTRY_INSIGHTS",
"name": "Sprout Social Brand"
}
]
Customer Teams Endpoint
GET /v1/<customer ID>/metadata/customer/teams
This endpoint is used to obtain the list of teams that are active for your customer.
Request Body - Customer Teams Endpoint
No request body is necessary for this request.
Response Data - Customer Teams Endpoint
The data array contains an array of JSON objects describing the active teams for your customer. The JSON object contains:
| Key | Description | Example Value |
|---|---|---|
id |
The ID used by Sprout to identify this team | "1234" |
name |
The name of the team | "Pricing Team" |
description |
The description of the team | "Answers pricing questions" |
An example response:
{
"data": [
{
"id": "1234",
"name": "Pricing Team",
"description": "Answers pricing questions"
},
...
]
}
Customer Case Queues Endpoint
GET /v1/<customer ID>/metadata/customer/queues
This endpoint is used to obtain the list of queues that are active for your customer.
Request Body - Customer Queues Endpoint
No request body is necessary for this request.
Response Data - Customer Queues Endpoint
The data array contains an array of JSON objects describing the active queues for your customer. The JSON object contains:
| Key | Description | Example Value |
|---|---|---|
id |
The ID used by Sprout to identify this queue | "5678" |
name |
The name of the queue | "Pricing Queue" |
description |
The description of the queue | "For streaming pricing questions" |
associated_teams |
An array of the IDs of the teams this queue is associated with | ["1234"] |
An example response:
{
"data": [
{
"id": "1234",
"name": "Pricing Team",
"description": "Answers pricing questions",
"associated_teams": [
"1234"
]
},
...
]
}
Analytics Endpoints
Analytics endpoints are all HTTP POST endpoints. They provide access to your owned profile and post analytics data, including:
- Profile Analytics - profile activity broken down by day
- Post Analytics - message content, metadata and lifetime activity metrics
Overview
All requests to and responses from Analytics API endpoints have a similar structure.
Requests - Analytics Endpoints
The request body for an analytics API request is a JSON object with the following name/values pairs:
| Key | Description | Example Value |
|---|---|---|
filters |
Detailed filters used to filter the results by customer_profile_id, reporting_period (for Profile metrics) and message created_time (for Posts endpoint). |
Profile Endpoint: ["customer_profile_id.eq(1234, 5678)", "reporting_period.in(2018-01-01...2018-02-01)"] Posts Endpoint: ["customer_profile_id.eq(1234, 5678)", "created_time.in(2018-01-01...2018-02-01)"] |
metrics |
List of metrics to return in results; refer to the metrics section for post and profile metrics available for each social network type | ["impressions", "likes"] |
page(optional) |
In paginated results, which 1-indexed page to return in the response. Pagination is based on default limits of 1000 results for the Profiles endpoint and 50 results for the Posts endpoint |
3 |
limit(optional) |
Specifies the max number of results per page in the response. Defaults to 1000 results for the Profiles endpoint and 50 results for the Posts endpoint. |
100 |
sort(optional) |
(Posts endpoint only) Sets the sort order for results, specified as a list of fields and directions ( asc or desc) in the format <field>:<direction>. |
["created_time:asc"] |
timezone(optional) |
(Posts endpoint only) Time zone—from the ICANN time zone database. Timezone arguments only impact date/time-related filters, responses are not impacted and are always in UTC for posts. |
"America/Chicago" |
fields(optional) |
(Posts endpoint only) List of fields to return in results; if omitted, only the guid field is returned. Refer to the Message Fields section for full list of valid fields |
["content_category", "created_time", "from.name"] |
Responses - Analytics Endpoints
Responses follow the standard data API response format:
data
This array contains the analytics data requested. See specific endpoints for additional details.
paging
This object specifies the state of paging for this response:
| Key | Description | Example Value |
|---|---|---|
current_page |
1-indexed page number of the response | 3 |
total_pages |
Total number of pages for the request | 20 |
A paging object is always returned, including when the response contains all data in one page. You can rely on checking for current_page = total_pages in order to know when you are at the end of the paging sequence.
Requesting a page greater than total_pages will return a HTTP 400 Bad Request response with a message describing the error.
Limitations
Note the maximum response size is capped at 10,000 results. For example, if a request with 50 responses per page is made,
you will get at most 200 total_pages back. Anything beyond this 10,000 limit will be truncated as a performance guardrail.
To request data for responses with more than 10,000 results, use a cursor-based pagination approach following these steps:
1.) Prepare the API URL for the specific endpoint you want to retrieve data from.
2.) Define the request body by specifying the necessary parameters like limit, timezone, filters, fields, and metrics criteria.
3.) Set the appropriate headers, including any required authentication or session information.
4.) Set the "sort" field to organize the response data by "guid" in ascending order
5.) Send an initial request to the API endpoint to retrieve a batch of data, specifying a limit on the number of items to be returned per request (e.g. 100 items per request).
6.) Process the sorted response data and extract the last "guid" value from the response. This "guid" will be used as the cursor for the next request.
7.) Send a subsequent request to the API endpoint. We’ll filter for posts with a guid greater than the guid we saw in the previous step to fetch the next batch of data. This request should also specify the limit and any other necessary parameters. See below for an example request to see how this is done.
8.) Repeat steps 2-7 until there are no more GUID's left in the response. Each time you receive a response, extract the last "guid" value, and use it to filter posts with greater guids for the following requests.
9.) As you receive the paginated responses, you can store or process the data as needed.
Initial Request:
{
"filters": [
"customer_profile_id.eq(123, 4567, 890)"
],
"fields": [
"guid"
],
"sort": [
"guid:asc"
],
"limit": 2
}
Initial Response:
{
"data": [
{
"guid": "101"
},
{
"guid": "102"
}
]
}
Subsequent Request:
{
"filters": [
"guid.gt(102)",
"customer_profile_id.eq(123, 4567, 890)"
],
"fields": [
"guid"
],
"sort": [
"guid:asc"
],
"limit": 2
}
Note that the last guid from the initial response (102) was used as a filter for the subsequent response ( "guid.gt(102)"). Each request thereafter should continue to filter on the last guid from the previous response until no more guids are returned.
Network Limitations
- To comply with the legal and partnership terms of service from Yelp/Trustpilot/TripAdvisor/Glassdoor, we cannot provide their data via our Public API. You can continue to view and manage all your reviews from these networks directly within the Sprout app.
- To comply with Google's terms of service, all data retrieved for Google My Business POST_TYPES will be limited to the last 30 days.
Owned Profile Analytics Endpoint
POST /v1/<customer ID>/analytics/profiles
The profiles endpoint is used to query profile-level metrics for a given set of profiles.
Request Body - Owned Profile Analytics Endpoint
An example request:
{
"filters": [
"customer_profile_id.eq(1234, 5678, 9012)",
"reporting_period.in(2018-08-01...2018-10-01)"
],
"metrics": [
"impressions",
"reactions"
],
"page": 1
}
Response Data - Owned Profile Analytics Endpoint
An example response:
{
"data" : [
{
"dimensions": {
"reporting_period.by(day)": "2018-08-01",
"customer_profile_id": 1234
},
"metrics": {
"impressions": 3400,
"reactions": 12
}
},
{
"dimensions": {
"reporting_period.by(day)": "2018-08-01",
"customer_profile_id": 5678
},
"metrics": {
"impressions": 23423,
"reactions": 29
}
},
...
],
"paging": {
"current_page": 2,
"total_pages": 3
}
}
Profile Request Limits & Pagination
customer_profile_id(filters): maximum of 100 profiles per requestreporting_period(filters): maximum of 1 year per request- Pagination of response: pagination is based on 1000 results per response
Profile Time Zone
Profile daily activity uses the time zone of the native network. These time zones are the same that are used by native networks when grouping profile level activity.
| Network | Timezone |
|---|---|
| X | UTC |
| PST/PDT | |
| PST/PDT | |
| UTC | |
| YouTube | PST/PDT |
| UTC | |
| Tiktok | UTC |
Post Analytics Endpoint
POST /v1/<customer ID>/analytics/posts
The posts content endpoint queries for individual sent posts based on a filter criteria.
Request Body - Post Analytics Endpoint
An example request:
{
"fields": [
"created_time",
"perma_link",
"text",
"internal.tags.id",
"internal.sent_by.id",
"internal.sent_by.email",
"internal.sent_by.first_name",
"internal.sent_by.last_name"
],
"filters": [
"customer_profile_id.eq(1234, 5678, 9012)",
"created_time.in(2020-04-06T00:00:00..2020-04-19T23:59:59)"
],
"metrics": [
"lifetime.impressions",
"lifetime.reactions"
],
"timezone": "America/Chicago",
"page": 1
}
Response Data - Post Analytics Endpoint
An example response:
{
"data": [
{
"text": "Come by for a cold brew!",
"perma_link": "https://www.instagram.com/p/B-pIo1GFqyl/",
"metrics": {
"lifetime.impressions": 15,
"lifetime.reactions": 0
},
"created_time": "2020-04-06T14:27:03Z",
"internal": {
"tags": [
{"id": 111111},
{"id": 111112},
{"id": 111113}
],
"sent_by": {
"id": 1155555,
"email": "sprout.user@sproutsocial.com",
"first_name": "Sprout",
"last_name": "User"
}
},
...
],
"paging": {
"current_page": 1,
"total_pages": 3
}
}
Post Request Limits & Pagination
customer_profile_id(filters): maximum of 100 profiles per request- Pagination of response: pagination is based on 50 messages per response
Messages Endpoint
POST /v1/<customer ID>/messages
The messages endpoint provides detailed data and metadata about your Sprout messages.
Requests - Messages Endpoint
The request body for a Messages request is a JSON object with the following name/values pairs:
| Key | Description | Example |
|---|---|---|
filters |
Refer to the Request Filters section below for details | ["group_id.eq(78910)", "customer_profile_id.eq(1234, 5678)", "created_time.in(2022-01-01..2022-02-01)"] |
fields(optional) |
List of fields to return in results. If omitted, only the guid field is returned. Refer to the Message Fields section for full list of valid fields |
["post_type", "created_time", "from.name", "text"] |
limit(optional) |
Specifies the max number of results per page in the response Default: 50, Max: 100 |
10 |
timezone(optional) |
Time zone — from the ICANN time zone database — used for period values | "America/Chicago" |
page_cursor(optional) |
In paginated results, specifies the next page of data to return. Pagination for the messages endpoint only supports fetching the 'next' page of data. See Messages Request Limits & Pagination section for details | "page_cursor": "abc123==" |
sort(optional) |
Return results sorted by message created_timeDefault: descending |
["created_time:asc"] |
Request Filters - Messages Endpoint
All requests to the Messages Endpoint require a filter parameter; the following table details the available filter options, which includes both required and optional filters:
| Filter Name | Description | Example Values |
|---|---|---|
group_id |
No more than one Group Id to retrieve messages for; selecting inbox_permalink is not supported if group_id isn't specified |
"group_id.eq(78910)" |
customer_profile_id |
One or more Profile ids to retrieve messages for; these profiles must all belong to the requested group_id |
"customer_profile_id.eq(1234, 5678)" |
message_id (mutually exclusive) |
One or more message GUIDs to retrieve; Must be used exclusively of all other filters | "message_id.eq(t:1234, p:5678)" |
created_time |
Only return messages having a created_time within the provided date range; accepts either dates or datetimes. Dates without timestamps are interpreted as midnight of that date, i.e. 2022-06-09 is treated as 2022-06-09T00:00:00 |
"created_time.in(2022-01-01...2022-02-01)" |
action_last_update_time(optional) |
Only return messages which have a Sprout action (Reply, Tag, Like or Complete) having an action_time within the provided date range; accepts either dates or datetimes. Dates without timestamps are interpreted as midnight of that date, i.e. 2022-06-09 is treated as 2022-06-09T00:00:00. This range cannot be chronologically before the created_time range |
"action_last_update_time.in(2022-01-01...2022-02-01)" |
post_type(optional) |
If provided, only messages of this type will be returned; defaults to all message types if omitted. Refer to the Post Types table for full list of valid post_types available for filtering | "post_type.eq(TWITTER_DIRECT_MESSAGE, INSTAGRAM_MEDIA)" |
tag_id(optional) |
If provided, only return messages with the specified tag_ids |
"tag_id.eq(123, 456, 789)" |
language_code(optional) |
If provided, only return messages with the specified language_codes |
"language_code.eq(en, es, fr)" |
from.guid(optional) |
One or more sender/external profile GUIDs to filter messages by the message author. Useful for narrowing results to messages from a specific profile or channel (for example ytpr:1234). |
"from.guid.eq(ytpr:1234)" |
Request Body - Messages Endpoint
Example request:
{
"filters": [
"group_id.eq(12345)",
"customer_profile_id.eq(1234, 5678, 9012)",
"created_time.in(2020-04-06T00:00:00..2020-04-19T23:59:59)",
"action_last_update_time.in(2020-08-06T00:00:00..2021-02-28T23:59:59)",
"post_type.eq(TWEET,FACEBOOK_POST,INSTAGRAM_DIRECT_MESSAGE)"
],
"fields": [
"network",
"activity_metadata.first_like.time_elapsed",
"created_time",
"post_category",
"post_type",
"perma_link",
"text",
"from",
"profile_guid",
"internal.tags.id",
"internal.sent_by.id",
"internal.sent_by.email"
],
"sort": ["created_time:desc"],
"limit": 50,
"timezone": "America/Chicago",
"page_cursor": "123abc=="
}
Responses - Messages Endpoint
Responses follow the standard Sprout API response format:
data
This array contains the message's data requested in JSON format.
paging (optional)
This object, if present, indicates there are still more pages of data to be fetched, and provides a cursor pointing to the next page of data:
| Key | Description | Example Value |
|---|---|---|
next_cursor |
String of alphanumeric characters representing the next page of data, sorted by message created_time |
"abcd1234==" |
Messages Request Limits & Pagination
-
message_id(filters): maximum of 100 messages per request -
Pagination of response is based on the following request params:
limit- number of messages returned per response (max: 100, default: 50)sort- sort order of messages in response; sorted by messagecreated_time(default: desc)
-
To paginate results: continuously fetch the "next" page of data, by updating the
page_cursorparameter, until a response without apagingobject is returned -
Note: Unlike some other Sprout API Endpoints, index-based paging (e.g.
page: 4) is not supported by the Messages Endpoint. While you can specify thesortdirection, you can only ever get the "next" page of data — you can't fetch the "previous" page -
A Request containing an invalid
page_cursorwill return a HTTP 400 Bad Request response with a message describing the error
Response Data - Messages Endpoint
Example response:
{
"data": [
{
"post_category": "POST",
"post_type": "INSTAGRAM_MEDIA",
"profile_guid": "placeholder",
"text": "placeholder",
"perma_link": "link here",
"network": "INSTAGRAM",
"internal": {
"tags": [
{
"id": 1234
},
{
"id": 5678
}
],
"sent_by": {
"id": 2066696,
"email": "___@sproutsocial.com",
"first_name": "placeholder",
"last_name": "placeholder"
}
},
"created_time": "2022-06-09T22:10:54Z"
},
...
],
"paging": {
"next_cursor": "456def=="
}
}
Limitations
Network Limitations
- To comply with the legal and partnership terms of service from Yelp/Trustpilot/TripAdvisor/Glassdoor, we cannot provide their data via our Public API. You can continue to view and manage all your reviews from these networks directly within the Sprout app.
- To comply with Google's terms of service, all data retrieved for Google My Business POST_TYPES will be limited to the last 30 days.
Direct Message Limitations
- The messages endpoint supports all direct message fields except media. Text and other metadata are retrievable. Media URLs returned for images or videos in DMs are nonfunctional.
Listening Endpoints
Listening endpoints are all HTTP POST endpoints. They provide access to your Listening Topic data, including:
- Messages - Enables you to query for messages within a given Topic.
- Metrics - Aggregates data across the Topic.
Overview
All requests to and responses from Listening API endpoints have a similar structure.
Requests - Listening Endpoints
The request body for a Listening API request is a JSON object with the following name/values pairs:
| Key | Description | Example Value |
|---|---|---|
filters |
Detailed filters used to filter the results by message created_time and network. To learn more about advanced filters for Topics see the Filters section. |
["created_time.in(2018-01-01...2018-02-01)"] |
metrics |
List of metrics to return in results; refer to the metrics | ["impressions", "likes"] |
fields |
List of fields to return in results; at least one field is required for Listening messages endpoint. Refer to the Listening Message Fields section for full list of valid fields | ["content_category", "created_time", "from.name"] |
page(optional) |
In paginated results, which 1-indexed page to return in the response. Pagination is based on default limits of 50 results |
3 |
limit(optional) |
Specifies the max number of results per page in the response. Defaults to 50 results for the Listening endpoints. | 100 |
sort(optional) |
Sets the sort order for results, specified as a list of fields and directions (asc or desc) in the format <field>:<direction>. |
["created_time:asc"] |
timezone(optional) |
Time zone—from the ICANN time zone database. Timezone arguments only impact date/time-related filters, responses are not impacted and are always in UTC for posts. | "America/Chicago" |
dimensions(optional) |
(Topic Metrics endpoints only) Breaks down metrics into discrete buckets. See Dimensions section to learn what fields work with dimensions. |
["created_time.by(day)", "sentiment"] |
Filters - Listening Endpoints
Filtering is a powerful query mechanism that allows you to isolate data within your Topics. You can combine most fields or metrics with the operators below to produce filter to specific data sets using the Topic Messages or Topic Metric endpoints.
| Operator | Description | Example Value |
|---|---|---|
gt |
Greater than | likes.gt(10) |
gte |
Greater than or equal to | engagement_total.gte(5) |
lt |
Less than | replies.lt(5) |
lte |
Less than or equal to | impressions.lte(1000) |
in |
Specifies a range. A helper that circumvents needed to use a filter with both gt and lt. Using .. is inclusive of the end value while ... is not. Dates and timestamps are accepted. Dates without timestamps are interpreted as midnight of that date, i.e. 2022-06-09 is treated as 2022-06-09T00:00:00. | created_time.in(2023-05-01…2023-06-01T23:59:59) |
eq |
Equals a particular value. Can contain multiple comma separated values. If multiple values are provided, the filter returns data containing at least one value. | network.eq(TWITTER,INSTAGRAM) |
neq |
The opposite of eq. | network.neq(FACEBOOK) |
exists |
Either true or false. Filter finds (or not) messages that meet the criteria of having a value (or not). | visual_media.exists(true) |
match |
Performs a text search query on a specified field. Multiple comma terms can be provided using spaces, wrap phrases or multiple words in quotes. Messages must match all provided terms. If you want a message that matches any single term, place an OR between terms (e.g. blue OR red). | text.match(blue OR red) text.match(“the blue car”) text.match(blue red green) |
You can apply multiple filters where data must meet all requirements by adding filters to the filters array. An example request using multiple filters:
{
"filters": [
"created_time.in(2022-11-28..2022-12-29T23:59:59)",
"text.match(blue car)",
"network.eq(INSTAGRAM,YOUTUBE,LINKEDIN,TUMBLR,WWW,TIKTOK,BLUESKY)"
]
}
Filtering by Data Source
Listening Topics can contain two types of data:
| Data Type | Description |
|---|---|
| Public Data | Messages generally collected without connected profile and must match your topic's query |
| Connected Profile Data | Messages from your Sprout Social connected profiles |
Requesting All Data for a Network (Public + Connected)
To retrieve all data—both public and from your connected profiles—for specific networks:
{
"filters": [
"created_time.in(2024-01-01..2024-01-31)",
"network.eq(FACEBOOK,INSTAGRAM)"
]
}
Requesting Public Data Only
To retrieve only public data (excluding your connected profiles), combine network.eq() with profile.neq() to exclude your connected profile IDs. You can exclude some or all of your profiles by including them in the profile.neq filter:
{
"filters": [
"created_time.in(2024-01-01..2024-01-31)",
"network.eq(FACEBOOK,INSTAGRAM)",
"profile.neq(12345,67890)"
]
}
Note: Profile IDs can be obtained from the customer metadata endpoints. Include all your connected profiles for the requested networks in profile.neq() to ensure only public data is returned.
Requesting Connected Profile Data Only
To retrieve data from only your connected profiles:
{
"filters": [
"created_time.in(2024-01-01..2024-01-31)",
"profile.eq(12345,67890)"
]
}
Responses - Listening Endpoints
Due to greater variability in response length, only the Messages endpoint supports paging. The Metrics endpoint does not support paging, and returns all data in a single response.
Responses follow the standard data API response format:
data
This array contains the Listening data requested. See specific endpoints for additional details.
paging
This object specifies the state of paging for this response:
| Key | Description | Example Value |
|---|---|---|
current_page |
1-indexed page number of the response | 3 |
total_pages |
Total number of pages for the request | 20 |
A paging object is always returned, including when the response contains all data in one page. You can rely on checking for current_page = total_pages in order to know when you are at the end of the paging sequence.
Requesting a page greater than total_pages will return a HTTP 400 Bad Request response with a message describing the error.
Dimensions - Listening Endpoints
Dimensions are a powerful tool that allow you to slice and bucket Topic metrics. The most common uses for dimensions would be generating metrics over time (e.g. a trend chart) or breaking down metrics by metadata such as sentiment score. The following Topic fields can be used as a dimension.
- created_time.by(day)
- created_time.by(month)
- visual_media.media_type
- distribution_type
- network
- sentiment
- language
- explicit_label
- location.city
- location.province
- location.country
Here is an example of multiple dimensions being used to create a trend chart of sentiment data over time:
{
"filters": [
"created_time.in(2022-11-28..2022-11-30)",
"network.eq(INSTAGRAM,YOUTUBE,LINKEDIN,TUMBLR,WWW,TIKTOK)"
],
"metrics": [
"replies",
"shares_count",
"likes"
],
"dimensions": [
"created_time.by(day)",
"sentiment"
],
"timezone": "America/Chicago"
}
Here is a sample output of this query:
{
"data": [
{
"dimensions": {
"created_time": "2022-11-30T00:00:00-06:00",
"sentiment": "positive"
},
"metrics": {
"replies": 29.0,
"shares_count": 5.0,
"likes": 557.0
}
},
{
"dimensions": {
"created_time": "2022-11-30T00:00:00-06:00",
"sentiment": "neutral"
},
"metrics": {
"replies": 17.0,
"shares_count": 5.0,
"likes": 354.0
}
},
{
"dimensions": {
"created_time": "2022-11-30T00:00:00-06:00",
"sentiment": "negative"
},
"metrics": {
"replies": 49.0,
"shares_count": 20.0,
"likes": 4725.0
}
}
],
"paging": {}
}
Topic Messages Endpoint
POST /v1/<customer ID>/listening/topics/<topic id>/messages
The Topic messages endpoint enables you to query for messages within a given Topic. The returning data set is an array of matching messages and the requested metrics or fields for each. This endpoint is best used to extract raw messages for further processing or providing sample messages within dashboards.
Request Body - Topic Messages Endpoint
An example request:
{
"filters": [
"created_time.in(2022-11-28..2022-12-29T23:59:59)",
"explicit_label.exists(false), explicit_label.eq(false)",
"network.eq(INSTAGRAM,YOUTUBE,LINKEDIN,TUMBLR,WWW,TIKTOK)"
],
"fields": [
"content_category",
"created_time",
"hashtags",
"language",
"location.city"
],
"metrics": [
"engagements",
"from.followers_count",
"likes",
"replies",
"shares_count",
"authors_count",
"positive_sentiments_count",
"neutral_sentiments_count",
"negative_sentiments_count"
],
"sort": [
"created_time:desc"
],
"timezone": "America/Chicago",
"limit": 50,
"page": 1
}
Response Data - Topic Messages Endpoint
An example response:
{
"data": [
{
"content_category": "PHOTO",
"guid": "17920699361640551",
"text": "Late post from Seattle trip \nColder than a blizzard in Alaska\n#seattle #seattlewashington #stevenspass #mtbakersnoqualmienationalforest #mtbaker #snoqualmiepass #snoqualmienationalforest #pikeplacemarket #pikeplace #seattlespaceneedle",
"perma_link": "https://www.instagram.com/p/CmxucH6L7T1/",
"network": "INSTAGRAM",
"visual_media": [
{
"media_url": "https://scontent-iad3-1.cdninstagram.com/v/t51.29350-15/323197452_926427338517295_6369335809654161527_n.jpg?_nc_cat=104&ccb=1-7&_nc_sid=8ae9d6&_nc_ohc=y4k7DO4QBHAAX8M7OZ1&_nc_ht=scontent-iad3-1.cdninstagram.com&edm=APCawUEEAAAA&oh=00_AfCps_5bFDmdZE-YVPDwVn5WF3XFWK4PWhd4-uRNTU2iCg&oe=643BF019",
"media_type": "PHOTO"
},
{
"media_url": "https://scontent-iad3-1.cdninstagram.com/v/t51.29350-15/322406676_8455452681195785_5328220517853332026_n.jpg?_nc_cat=101&ccb=1-7&_nc_sid=8ae9d6&_nc_ohc=VpBu3GAXQqoAX_K5LU3&_nc_ht=scontent-iad3-1.cdninstagram.com&edm=APCawUEEAAAA&oh=00_AfD4SCutTw_J7hPbzUJNpAEyaoXd6kBmzHJM-MINZapJmg&oe=643CCB3C",
"media_type": "PHOTO"
},
{
"media_url": "https://scontent-iad3-1.cdninstagram.com/v/t51.29350-15/322520040_494039015961334_6394396172311331958_n.jpg?_nc_cat=101&ccb=1-7&_nc_sid=8ae9d6&_nc_ohc=t6xksNZv91kAX9rE5mL&_nc_ht=scontent-iad3-1.cdninstagram.com&edm=APCawUEEAAAA&oh=00_AfBgn_HEqLsn269mk4oAFXQmbSrbRbxzpbrfwXZLg2F2YQ&oe=643BA80B",
"media_type": "PHOTO"
},
{
"media_url": "https://scontent-iad3-2.cdninstagram.com/v/t51.29350-15/322386857_955848772063194_984682163981872244_n.jpg?_nc_cat=105&ccb=1-7&_nc_sid=8ae9d6&_nc_ohc=zIh0QFX3T50AX95k8wg&_nc_ht=scontent-iad3-2.cdninstagram.com&edm=APCawUEEAAAA&oh=00_AfB7_8ChB-7nq4MXdOaIatp0sCw4ZXqEOoikh-cCoEUIGA&oe=643BE125",
"media_type": "PHOTO"
},
{
"media_url": "https://scontent-iad3-1.cdninstagram.com/v/t51.29350-15/322393885_1262531494303623_5396853589364944362_n.jpg?_nc_cat=102&ccb=1-7&_nc_sid=8ae9d6&_nc_ohc=uzwo3FqbohgAX_wtdqq&_nc_ht=scontent-iad3-1.cdninstagram.com&edm=APCawUEEAAAA&oh=00_AfAZmRdk8Va92UX3FmnjMJo_wf2rxwP5E_5ExT4-TWSSpA&oe=643BD1F1",
"media_type": "PHOTO"
},
{
"media_url": "https://scontent-iad3-1.cdninstagram.com/v/t51.29350-15/322830314_217584514039146_7428674933900498885_n.jpg?_nc_cat=110&ccb=1-7&_nc_sid=8ae9d6&_nc_ohc=m2PtitrP1A0AX8f6gso&_nc_ht=scontent-iad3-1.cdninstagram.com&edm=APCawUEEAAAA&oh=00_AfD6KYXBQVk_BNNQ0FUM8NihyH08v7QF_t61BY3mFdu7sA&oe=643B60F6",
"media_type": "PHOTO"
},
{
"media_url": "https://scontent-iad3-2.cdninstagram.com/v/t51.29350-15/322294142_738549953871939_8482926741552785486_n.jpg?_nc_cat=111&ccb=1-7&_nc_sid=8ae9d6&_nc_ohc=k8lcfSt9dhMAX_FZEyt&_nc_ht=scontent-iad3-2.cdninstagram.com&edm=APCawUEEAAAA&oh=00_AfAQYi1Lx_i-c-SRkWt6tfuhptuuvFx2PlBN1b6fb7kFGA&oe=643CA58A",
"media_type": "PHOTO"
},
{
"media_url": "https://scontent-iad3-1.cdninstagram.com/v/t51.29350-15/322601354_1215109445751814_6654433182308805760_n.jpg?_nc_cat=107&ccb=1-7&_nc_sid=8ae9d6&_nc_ohc=XsbPztVyu-4AX8vsyjC&_nc_ht=scontent-iad3-1.cdninstagram.com&edm=APCawUEEAAAA&oh=00_AfBdQ9GECTdbNtQ-06ruuXQVsN5qPrwKnGsghbaj8uPjig&oe=643B6CDE",
"media_type": "PHOTO"
}
],
"hashtags": [
"seattlespaceneedle",
"snoqualmienationalforest",
"seattle",
"stevenspass",
"pikeplace",
"seattlewashington",
"mtbakersnoqualmienationalforest",
"mtbaker",
"pikeplacemarket",
"snoqualmiepass"
],
"created_time": "2022-12-30T03:27:02Z",
"listening_metadata": {
"sentiment": "neutral",
"explicit_label": false,
"language": "en"
}
}
],
"paging": {
"current_page": 1
}
}
Listening Messages Request Limits and Pagination
- Pagination of response is based on the following request params:
limit- number of messages returned per response (max: 100, default: 50)sort- sort order of messages in response; sorted by messagecreated_time(default: desc)
Topic Metrics Endpoint
POST /v1/<customer ID>/listening/topics/<topic id>/metrics
The Topic metrics endpoint aggregates data across the Topic. Use this endpoint when you need answers related to key metrics such as total Topic volume, engagement, etc. or trends over time. This endpoint is best for quick insights or building complex dashboards.
Request Body - Topic Metrics Endpoint
An example request:
{
"filters": [
"created_time.in(2022-11-28..2022-12-29T23:59:59)",
"network.eq(INSTAGRAM,YOUTUBE,LINKEDIN,TUMBLR,WWW,TIKTOK)",
"sentiment.eq(positive,negative,neutral,unclassified)"
],
"metrics": [
"replies",
"shares_count",
"likes"
],
"dimensions": [
"sentiment"
],
"timezone": "America/Chicago"
}
Response Data - Topic Metrics Endpoint
An example response:
{
"data": [
{
"dimensions": {
"sentiment": "POSITIVE"
},
"metrics": {
"replies": 178563.0,
"shares_count": 55535.0,
"likes": 7221913.0
}
},
{
"dimensions": {
"sentiment": "NEGATIVE"
},
"metrics": {
"replies": 38758.0,
"shares_count": 43396.0,
"likes": 468540.0
}
},
{
"dimensions": {
"sentiment": "NEUTRAL"
},
"metrics": {
"replies": 14252.0,
"shares_count": 25529.0,
"likes": 807694.0
}
},
{
"dimensions": {
"sentiment": "UNCLASSIFIED"
},
"metrics": {
"replies": 31900.0,
"shares_count": 17977.0,
"likes": 1074959.0
}
}
]
}
Listening Metrics Request Limits and Sorting
- Response length is based on the following request params:
limit- number of metrics objects returned per response
Publishing Post Endpoints
Overview
Create and manage Publishing posts within Sprout that are intended to be published to social networks at a future time.
- Create Publishing Post - Create a Publishing Post (currently only supports posts in Draft status)
- Retrieve Publishing Post - Retrieve a Publishing Post by its
publishing_post_id
Limitations
- Only posts created in draft status are supported at this time.
- Instagram Mobile Publisher and story posts cannot be created directly; those will be created as media posts and can be updated within the Sprout UI.
- Supports the following profile types: Instagram Business and Creator, Facebook Pages, Threads, X, LinkedIn Pages and Personal, YouTube, TikTok, Pinterest, and Google My Business
- At this time a post retrieved by its
publishing_post_idwill always have adelivery_status: PENDING, even if it has already been published. To retrieve a post that has already been published, use the Messages Endpoint . - If a request includes multiple profiles and the attached media is not supported for one of those profiles, the unsupported profile will be dropped. No error is returned, and the draft post will only be created for profiles in which that media type or limit is supported. For example, a request to create a post with a PDF file with both a LinkedIn profile and an Instagram profile will result in only a LinkedIn draft post. You can reference Sprout Social’s Help Center for a comprehensive list of accepted media by network: https://support.sproutsocial.com/hc/en-us/articles/115003659326-Media-Upload-Types-and-Size-Limits.
Requests - Publishing Post Endpoints
The request body for a Publishing Post API request is a JSON object with the following fields:
| Key | Description | Example Value |
|---|---|---|
group_id |
ID of the group in which to create the post | 55667788 |
customer_profile_ids |
ID of the profile(s) for which to publish the post. Multiple profiles on a post must exist within the same group. |
[2345, 5678] |
is_draft |
Indicates whether the post should be created in draft status. Currently all posts require "is_draft": true as only draft post creation is supported. |
true |
text (optional - per network) |
Text of the post. | "Post text" |
media (optional - per network) |
Array of media object(s) for post media. The order of objects in this array determines the media order on the post. | [{"media_id": "1234-abcd-7890", "media_type": "PHOTO"}, {"media_id": "1234-wxzy-7890", "media_type": "VIDEO"}, {"media_id": "1234-efgh-7890", "media_type": "DOCUMENT"}] |
media.media_id |
Media ID obtained from Media Upload endpoint | "1234-abcd-7890" |
media.media_type |
Supported values are PHOTO, VIDEO, and DOCUMENT |
"PHOTO" |
delivery (optional) |
Container for post delivery details. Only required for draft scheduled posts. | {"scheduled_times": ["2024-06-30T18:20:00Z"], "type": "SCHEDULED"} |
delivery.scheduled_times |
Array of iso8601 timestamps in UTC, representing the delivery date and time of the post. Scheduled times must be in the future and any seconds will be rounded down to the nearest minute. |
["2024-10-14T15:00:00Z", "2023-10-16T18:00:00Z"] |
delivery.type |
Only SCHEDULED is supported at this time |
"SCHEDULED" |
tag_ids(optional) |
Array of tag IDs to apply to the post | [123, 456] |
Create Publishing Post Endpoint
POST /v1/<customer ID>/publishing/posts
Create a Publishing Post in Sprout that is intended to be published at a future time. Creating a Post via the API will create one or more posts on the Sprout Publishing Calendar.
Draft Post Fan-out
For draft posts, the current behavior in Sprout and via the API will be to create one post on the calendar per profile on the post (this is referred to as “fan-out”). The unique publishing_post_id in the response will represent a single post on the Sprout Publishing Calendar.
The API response will not represent the single post on the Sprout Publishing Calendar but instead represent the posts as they would appear on social networks as they would be published in the future. For example, a post created with two profiles (one Facebook, one Instagram) will be represented by two objects in the response: one representing the future Instagram post and the other representing the future Facebook Post.
Another dimension is possible if the post is scheduled for multiple send times.
For example, if a post has two profiles (one Facebook, one Instagram) and two scheduled send times, the response will contain four objects: two Instagram posts and two Facebook posts, each containing the deliveries object with one of the scheduled delivery times.
Request Body - Create Publishing Post Endpoint
An example request:
{
"group_id": 55667788,
"customer_profile_ids": [
2345,
5678
],
"is_draft": true,
"text": "A draft post",
"delivery": {
"scheduled_times": [
"2024-06-30T18:20:00Z"
],
"type": "SCHEDULED"
},
"media": [
{
"media_id": "1234-abcd-7890",
"media_type": "PHOTO"
}
]
}
Response Data - Publishing Post Endpoints
An example response:
{
"data": [
{
"post_category": "POST",
"post_type": "FACEBOOK_POST",
"customer_profile_id": "2345",
"profile_guid": "fbpr:1112345",
"internal": {
"publishing": {
"publishing_post_id": 4567890,
"group_id": 55667788,
"is_draft": true,
"text": "A draft post",
"perma_link": "https://app.sproutsocial.com/publishing/activity/1234/4567890",
"deliveries": [
{
"type": "SCHEDULED",
"delivery_status": "PENDING",
"scheduled_time": "2024-06-30T18:20:00Z"
}
],
"media": [
{
"id": "6789-defg-5678",
"media_type": "PHOTO"
}
],
"created_by": {
"id": 1155555,
"email": "sprout.user@sproutsocial.com",
"first_name": "Sprout",
"last_name": "User"
},
"updated_by": {
"id": 1155555,
"email": "sprout.user@sproutsocial.com",
"first_name": "Sprout",
"last_name": "User"
},
"created_time": "2024-06-24T19:44:32Z",
"updated_time": "2024-06-24T19:44:32Z"
}
}
},
{
"post_category": "POST",
"post_type": "INSTAGRAM_MEDIA",
"customer_profile_id": "5678",
"profile_guid": "ibpr:5556789",
"internal": {
"publishing": {
"publishing_post_id": 4567891,
"group_id": 55667788,
"is_draft": true,
"text": "A draft post",
"perma_link": "https://app.sproutsocial.com/publishing/activity/1234/4567891",
"deliveries": [
{
"type": "SCHEDULED",
"delivery_status": "PENDING",
"scheduled_time": "2024-06-30T18:20:00Z"
}
],
"media": [
{
"id": "6789-defg-5678",
"media_type": "PHOTO"
}
],
"created_by": {
"id": 1155555,
"email": "sprout.user@sproutsocial.com",
"first_name": "Sprout",
"last_name": "User"
},
"updated_by": {
"id": 1155555,
"email": "sprout.user@sproutsocial.com",
"first_name": "Sprout",
"last_name": "User"
},
"created_time": "2024-06-24T19:44:32Z",
"updated_time": "2024-06-24T19:44:32Z"
}
}
}
]
}
Retrieve Publishing Post Endpoint
GET /v1/<customer ID>/publishing/posts/<publishing_post_id>
Retrieve a Publishing Post by its publishing_post_id. If multiple profiles or send times are present on the post, the response will contain the "fanned-out" posts as they would appear on social networks in the future.
Response Data - Retrieve Publishing Post Endpoint
An example response:
{
"data": [
{
"post_category": "POST",
"post_type": "FACEBOOK_POST",
"customer_profile_id": "2345",
"profile_guid": "fbpr:1112345",
"internal": {
"publishing": {
"publishing_post_id": 4567890,
"group_id": 55667788,
"is_draft": true,
"text": "A draft post",
"perma_link": "https://app.sproutsocial.com/publishing/activity/1234/4567890",
"deliveries": [
{
"type": "SCHEDULED",
"delivery_status": "PENDING",
"scheduled_time": "2024-06-30T18:20:00Z"
}
],
"media": [
{
"id": "6789-defg-5678",
"media_type": "PHOTO"
}
],
"created_by": {
"id": 1155555,
"email": "sprout.user@sproutsocial.com",
"first_name": "Sprout",
"last_name": "User"
},
"updated_by": {
"id": 1155555,
"email": "sprout.user@sproutsocial.com",
"first_name": "Sprout",
"last_name": "User"
},
"created_time": "2024-06-24T19:44:32Z",
"updated_time": "2024-06-24T19:44:32Z"
}
}
}
]
}
Simple Media Upload
POST /v1/<customer ID>/media/
The media upload system works with other parts of the public API that require media existing in the Sprout Social systems. This media upload system supports three different means to send content to sprout:
- Simple Media Upload
- Media files are limited to 50MiB in size
- Multipart Media Upload
- This scheme relies on uploading a media file 5MiB at a time
- Download from a Link
- This scheme relies on a publicly available internet reachable file on http/https hosted URLs
- This scheme is built into the single upload or multipart upload paths, and can be treated as either depending on what makes sense for the media file in question. See the individual API endpoint definitions below for the caveats of using one over the other.
Limitations
-
Media sent to Sprout via this API are normally retained for 24 hours before it is removed unless used by other API operations
-
Currently, the only applicable use of uploaded media is to be used alongside post submissions.
-
Uploaded media must be identified as one of the specified supported media types:
Content Type Common Extension image/png png image/gif gif image/webp webp image/jpeg jpg image/heic heic image/avif avif video/x-msvideo avi video/quicktime mov video/mp4 mp4 video/mpeg mpg image/heic-sequence heifs video/hevc hevc video/avc avc video/av1 av1 image/x-heif-jpeg jpeg image/heif heif video/webm webm video/x-matroska mkv application/x-matroska mkv application/x-subrip srt application/pdf pdf - ** Note: Although this API supports these content types, the target social networks have their own rules on media files which need to be honored. Sprout will not transcode these files into network compatible versions when used with posts. There are some built-in validation rules we enforce when a media file is used with pending posts, but these limitations may not catch every case where a social network rejects a given media file. See this help center page for details on known social network media limitations.
This endpoint supports uploading a media file in a single request or to request a link download for a media file existing on the internet.
The request format of this endpoint is multipart/form-data. The request must contain one of two request part names to be provided in each request:
- media - (Single File Upload) The media file contents in bytes
- The part may contain an optional content disposition which specifies the original content type and file name of the media. Sending this information may help to identify the source content, but it is not mandatory
- media_url - (Link Download via Single File Upload) A UTF-8 text part containing the HTTP/HTTPS URL of a media file on the internet
Response
A response code of 200 indicates that the part was submitted successfully. Any other status should be accompanied by a descriptive error for why it failed. Generally, requests in the 4xx code range are fatal errors that require a new media request, whereas 5xx failures are temporary and can be retried with an exponential back-off retry policy.
On a successful transfer, the resulting payload will be a JSON document containing a media_id text field which can then be used by other API calls when associating said media with post creation activities. The response also contains an expiration_time which shows how long the media will be available for use in a pending post. Any requests associating with this expiration time will fail.
Limitations
- Media sent directly larger than 50 MiB will be rejected
- Media content that is not identified as a know media type will be rejected
- For link download requests, the network request will remain open and not respond until the link download request has been authorized and fully downloaded.
- This transaction trades the convenience of a single request/response with the limitation that the link download needs to complete before a network timeout in order to succeed. If you see consistent sets of timeouts when submitting link download requests on this endpoint, it's advisable to switch to the multipart upload API for link downloads.
Example Request (Simple File Upload)
curl -s -X POST \
--form "media=@$MEDIA_DIR/$MEDIA_FILE;type=image/gif" \
https://api.sproutsocial.com/v1/$CUSTOMER/media/ \
-H "authorization: Bearer $TOKEN" \
-H "Content-Type: multipart/form-data"
Response:
{
"data": [
{
"media_id": "565fc90f-dd98-4c84-ab17-6f051fb536ce",
"expiration_time": "2023-10-12T11:20:16Z"
}
]
}
Example Request (Link Download via Simple File Upload)
curl -s -X POST \
--form "media_url=https://my.public.media.com/my_file.jpg" \
https://api.sproutsocial.com/v1/$CUSTOMER/media/ \
-H "authorization: Bearer $TOKEN" \
-H "Content-Type: multipart/form-data"
Response:
{
"data": [
{
"media_id": "565fc90f-dd98-4c84-ab17-6f051fb536ce",
"expiration_time": "2023-10-12T11:20:16Z"
}
]
}
Multipart Media Upload
Multipart uploads become necessary when managing files larger than 50 MiB, or when media content is expected to take longer to download via link downloading. This benefit is traded with needing to perform multiple requests to the API in order to achieve similar objectives.
Processing Steps
- Initiate a new request for a Multipart upload using the
Start multipart media uploadsteps below.- A successful response here will return a JSON
submission_idwhich will be needed in each subsequent step - The multipart media request must be completed and used within 24 hours of this initial request
- A successful response here will return a JSON
- Upload all other parts of the media file using the
Continue multipart media uploadsteps below.- Each file part must be a sequential whole number. The initial upload is considered part 1, so each subsequent part must be 2, 3, 4, etc. until the file is entirely uploaded.
- This can be done sequentially, or in parallel
- Once all parts have been uploaded, finish the upload processing by using the
Complete multipart media uploadsteps below.
Limitations
- All media parts uploaded must be exactly 5MiB (5,242,880 bytes) except for the last upload part, which can be any size > 0 bytes
- For files < 5 MiB send via this API, the "Start multipart media upload" step can receive a file under 5 MiB as long as no subsequent parts are sent.
- Media content that is not identified as a know media type will be rejected. This content ID will only occur on the first 5 MiB part of the media, so a failed identification within that file chunk will cause the request to fail
Start multipart media upload
POST /v1/<customer ID>/media/submission
This endpoint supports uploading a media file in a single request or to request a link download for a media file existing on the internet.
The request format of this endpoint is multipart/form-data. The request must contain one of two request part names to be provided in each request:
- media - The media file part contents in bytes
- The part may contain an optional content disposition which specifies the original content type and file name of the media. Sending this information may help to identify the source content, but it is not mandatory
- media_url - (Link Download) A UTF-8 text part containing the HTTP/HTTPS URL of a media file on the internet.
- When if successful, skip to
Complete multipart media uploadto await the completion of the link download requested.
- When if successful, skip to
Response
A response code of 200 indicates that the part was submitted successfully. Any other status should be accompanied by a descriptive error for why it failed. Generally, requests in the 4xx code range are fatal errors that require a new media request, whereas 5xx failures are temporary and can be retried with an exponential back-off retry policy.
On a successful request, the resulting payload will be a JSON document containing a submission_id text field. This field is needed for the follow-up Continue multipart media upload and Complete multipart media upload steps.
Example Request
curl -s -X POST \
--form "media=@$MEDIA_DIR/$MEDIA_FILE_PART_1;type=image/gif" \
https://api.sproutsocial.com/v1/$CUSTOMER/media/submission \
-H "authorization: Bearer $TOKEN" \
-H "Content-Type: multipart/form-data"
Response:
{
"data": [
{
"submission_id": "565fc90f-dd98-4c84-ab17-6f051fb536ce"
}
]
}
Example Request (Link Download)
curl -s -X POST \
--form "media_url=https://my.public.media.com/my_file.jpg" \
https://api.sproutsocial.com/v1/$CUSTOMER/media/submission \
-H "authorization: Bearer $TOKEN" \
-H "Content-Type: multipart/form-data"
Response:
{
"data": [
{
"submission_id": "565fc90f-dd98-4c84-ab17-6f051fb536ce"
}
]
}
Continue multipart media upload
POST /v1/<customer ID>/media/submission/<submission_id>/part/<part_number>
If the media file part uploaded in Start multipart media upload was 5 MiB, and there are still more bytes to upload, the continue multipart media endpoint needs to be called continually with each part of the media file until its entirely uploaded. It uses the same multipart/form-data structure as the initial submission URL, but this one is slightly different.
- The URL contains a part number. It must represent a whole number starting at
2. This continues ascending (3,4,5,etc...) until you've upload all the data bytes of the source media. - The form's
mediadisposition is not needed and will be ignored. The content type of this data is implicitly application/octet-stream
There are no requirements about executing these upload parts in parallel if desired. If any part submission fails, they can be uploaded again as long as the 24-hour expiration hasn't lapsed on the original upload request and as long as the final completion step hasn't been executed.
Response
A response code of 200 indicates that the part was submitted successfully. Any other status should be accompanied by a descriptive error for why it failed. Generally, requests in the 4xx code range are fatal errors that require a new media request, whereas 5xx failures are temporary and can be retried with an exponential back-off retry policy.
This API endpoint has no payload response when it succeeds.
Example Request(s)
curl -s -X POST \
--form "media=@$MEDIA_DIR/$MEDIA_FILE_PART_2" \
https://api.sproutsocial.com/v1/$CUSTOMER/media/submission/$SUBMISSIONID/part/2 \
-H "authorization: Bearer $TOKEN" \
-H "Content-Type: multipart/form-data"
curl -s -X POST \
--form "media=@$MEDIA_DIR/$MEDIA_FILE_PART_3" \
https://api.sproutsocial.com/v1/$CUSTOMER/media/submission/$SUBMISSIONID/part/3 \
-H "authorization: Bearer $TOKEN" \
-H "Content-Type: multipart/form-data"
Response:
A response code of 200 indicates that the part was submitted successfully. Any other status should be accompanied by a descriptive error for why it failed.
(no body response)
Complete multipart media upload
GET /v1/<customer ID>/media/submission/<submission_id>
Response
A response code of 200 or 202 indicates that the request was good. Any other status should be accompanied by a descriptive error for why it failed. Generally, requests in the 4xx code range are fatal errors that require a new media request, whereas 5xx failures are temporary and can be retried with an exponential back-off retry policy.
Example Request (Not ready)
curl -s -X GET \
https://api.sproutsocial.com/v1/$CUSTOMER/media/submission/$SUBMISSIONID \
-H "authorization: Bearer $TOKEN"
Response:
HTTP Status 202 indicates that the request is good, but the media is not ready to be served yet. This process can take
seconds to minutes depending on the size of the content and if it was a link download or direct upload. If you receive
this response, please defer retrying the request until the wait_until time has lapsed. If a high number of calls occur
in a short duration, the requests could be rate limited and further complicate the processing of this request.
{
"data": [
{
"submission_id": "febca520-f44e-4b7c-b451-04a911c53f0f",
"wait_until": "2024-04-22T17:03:21.600802351Z"
}
]
}
Example Request (ready)
HTTP Status 200 indicates that the request succeeded and that the media_id returned in the response body is now good
to use in other subsequent API requests.
Response:
{
"data": [
{
"media_id": "565fc90f-dd98-4c84-ab17-6f051fb536ce",
"expiration_time": "2023-10-12T11:20:16Z"
}
]
}
Cases Endpoints
Request - Filter Cases
POST /v1/<customer ID>/cases/filter
This endpoint provides information about your Sprout cases.
Requests - Cases Endpoint
The request body for a Cases request is a JSON object with the following name/values pairs
| Key | Description | Example |
|---|---|---|
filters |
Refer to the Request Filters section below for details | ["updated_time.in(2025-01-01...2025-01-08)", "priority.eq(HIGH, LOW, UNDEFINED)"] |
limit (optional) |
Specifies the max number of results per page in the response Default: 50 Max: 100 | 10 |
timezone (optional) |
Time zone — from the ICANN time zone database — used for period values Default: "America/Chicago" |
"America/Chicago" |
page_cursor (optional) |
In paginated results, specifies the next page of data to return. Pagination for the cases endpoint only supports fetching the 'next' page of data. See Cases Request Limits & Pagination section for details | "page_cursor": "abc123==" |
sort (optional) |
Return results sorted by case created_time or updated_time Default: created_time: descending |
["created_time:asc"] |
Request Filters - Cases Endpoint
All requests to the Cases Endpoint require at least one filter parameter: either a case_id and no other filters or at least one date filter with a maximum range of one-week. The following table details the available filter options, which include both required and optional filters:
| Filter Name | Description | Example Values |
|---|---|---|
case_id (mutually exclusive) |
Only return cases with these case ids. Must be used exclusively of all other filters. | case_id.eq(23, 42) |
created_time* (optional) |
Only return cases having a created_time within the provided date range (up to one week); accepts either dates or datetimes. Dates without timestamps are interpreted as midnight of that date, i.e. 2025-01-01 is treated as 2025-01-01T00:00:00 | created_time.in(2025-01-01...2025-01-08) |
latest_activity_time* (optional) |
Only return cases that have their latest activity (case updates, internal comments, and social messages) within the provided date range (up to one week). Accepts either dates or datetimes. Dates without timestamps are interpreted as midnight of that date, i.e. 2025-01-01 is treated as 2025-01-01T00:00:00. This range cannot be chronologically before the created_time range. | latest_activity_time.in(2025-01-01...2025-01-08) |
updated_time* (optional) |
Only return cases that have had their metadata updated (i.e. assignee, status, etc) within the provided date range (up to one week). This does not factor in new messages received or internal comments added to the case. See latest_activity_time. Accepts either dates or datetimes. Dates without timestamps are interpreted as midnight of that date, i.e. 2025-01-01 is treated as 2025-01-01T00:00:00. This range cannot be chronologically before the created_time range. |
updated_time.in(2025-01-01...2025-01-08) |
queue_id (optional) |
Only cases routed to specified queue will be returned; defaults to any queue assignment if omitted. | queue_id.eq(23) |
type (optional) |
Only cases of this type will be returned; defaults to all types if omitted. Valid Types: GENERAL, SUPPORT, LEAD, QUESTION, FEEDBACK | type.eq(GENERAL, SUPPORT, LEAD, QUESTION, FEEDBACK) |
priority (optional) |
If provided, only cases of this priority will be returned; defaults to all priorities if omitted. Valid Priorities: HIGH, LOW, CRITICAL, MEDIUM, UNDEFINED | priority.eq(HIGH, LOW, CRITICAL, MEDIUM, UNDEFINED) |
status (optional) |
Only cases of this status will be returned; defaults to all statuses if omitted. Valid Statuses: OPEN, ON_HOLD, CLOSED | status.eq(OPEN, ON_HOLD, CLOSED) |
message_id (optional) |
Only cases related to these message guids, will be returned; defaults to all messages if omitted. *when using the messages endpoint to retrieve the message, make sure you have signed the agreement with X or X message guids will not be returnable | message_id.eq(igdm:aWdddfZAG1faXRlbToxOklHTWVz) |
tag_id (optional) |
Only cases related with the tags ids will be returned; defaults to any tags if omitted. | tag_id.eq(123,633,103) tag_id.neq(123,431,103) |
assigned_by (optional) |
Only cases assigned by these urns will be returned; defaults to any assigner if omitted. | assigned_by.eq(urn:spt:core:account_login:1420065, urn:spt:core:automated_rule:12345) |
created_by (optional) |
Only cases created by these urns will be returned; defaults to any created_by if omitted. | created_by.eq(urn:spt:core:accont_login:8989, urn:spt:core:automated_rule:12345) |
assigned_to (optional) |
Only cases assigned to these urns will be returned; defaults to all assignees if omitted. | assigned_to.eq(urn:spt:core:account_login:1420065) |
Request Body - Cases Endpoint
Example request:
{
"filters": [
"created_by.eq(urn:spt:core:account_login:89829)",
"created_time.in(2025-02-06T00:00:00..2020-02-12T23:59:59)",
"updated_time.in(2025-02-10...2025-02-13)",
"priority.eq(HIGH, LOW, UNDEFINED)",
"status.eq(OPEN, IN_PROGRESS, ON_HOLD, CLOSED)",
"assigned_to.eq(urn:spt:core:account_login:1420065)",
"type.eq(general, support, lead, question, feedback)",
"queue_id.eq(23234)",
"message_id.eq(igdm:aWdddfZAG1faXRlbToxOklHTWVz)"
],
"sort": [
"created_time:desc"
],
"limit": 50,
"timezone": "America/Chicago",
"page_cursor": "123abc=="
}
Example request for cases by ID:
{
"filters": [
"case_id.eq(123,456,789)"
],
"sort": [
"created_time:desc"
],
"timezone": "America/Chicago",
"page_cursor": "123abc=="
}
Responses - Cases Endpoint
Responses follow the standard Sprout API response format:
data
This array contains the case's data requested in JSON format.
Paging (optional)
This object, if present, indicates there are still more pages of data to be fetched, and provides a cursor pointing to the next page of data:
| Key | Description | Example Value |
|---|---|---|
next_cursor |
String of alphanumeric characters representing the next page of data, sorted by case created_time or updated time |
"abcd1234==" |
Cases Request Limits & Pagination
Case_id(filters): maximum of 100 case id’s per request- Pagination of response is based on the following request params:
limit- number of cases returned per response (max: 100, default: 50)sort- sort order of cases in response; sorted by casecreated_time, or updated_time(default: created_time: desc)
- To paginate results: continuously fetch the "next" page of data, by updating the
page_cursorparameter, until a response without apagingobject is returned - Note: Unlike some other Sprout API Endpoints, index-based paging (e.g.
page: 4) is not supported by the Cases Endpoint. While you can specify thesortdirection, you can only ever get the "next" page of data — you can't fetch the "previous" page
Response Data - Cases Endpoint
Note: The type field may be null for cases not associated with a specific type.
Example response:
{
"case_id": "19508937",
"type": "general",
"group_id": "1196505",
"priority": "LOW"
"status": "CLOSED",
"messages" : {[
"guid": "d:1747273869747175550",
“msg_created_date”: "2024-06-09T22:10:54Z",
"case_message_direction": "RECEIVED",
"is_anchor": true
]},
"created_by": "urn:spt:core:account_login:2372804",
"created_time": "2024-06-09T22:10:54Z",
"updated_time": "2024-08-09T22:10:54Z",
"last_closed_time": "2024-10-09T22:10:54Z",
"queue_id": "756",
"assigned_to": ["urn:spt:core:account_login:2372804"],
"assigned_by": "urn:spt:core:account_login:2372804",
"tags": {[
“tag_id”: 2323132
“updated_by”: "urn:spt:core:account_login:2372804"
“updated_time”: "2024-08-09T22:10:54Z"
]}
}
Metrics and Fields
Message Metadata
Message Fields
| Key | Type | Network Availability | Notes |
|---|---|---|---|
content_category |
STRING |







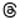

|
Unified categorization of the content. The hierarchy is album, video, photo, link, poll or text. |
created_time |
DATE |


|
An iso8601 timestamp representing the publication date and time of the message. |
from |
MAP |
|
A shorthand for requesting all of the following "from" nested fields. Represents the social network profile that published the message. |
from.guid |
STRING |
|
The native ID of the authors' profile prefixed with a Sprout code that represents where the data was collected. |
from.name |
STRING |
|
The display name of the author. |
from.profile_picture |
STRING |
|
URL to the profile picture. |
from.screen_name |
STRING |
|
Also commonly called "handle," this field is mutable on most networks, but not changed as often as the display name. |
guid |
STRING |
|
The native ID of the message prefixed with a Sprout code that represents where this type of message is. |
customer_profile_id |
NUMBER |
|
ID of the profile associated with this message. Corresponds to the customer_profile_id in the requested filters. |
internal |
MAP |
|
A shorthand for requesting internal.tags.id and internal.sent_by.id. |
internal.tags.id |
ARRAY<NUMBER> |
|
Array of tag IDs this message is associated with. Includes active and archived tags. Note that if group_id is specified, only tags scoped to that group_id will be included. |
internal.sent_by.id |
NUMBER |
|
ID of the team member that sent this message via Sprout. |
internal.sent_by.email |
STRING |
|
Email address of the team member that sent this message. |
internal.sent_by.first_name |
STRING |
|
First name of the team member that sent this message. |
internal.sent_by.last_name |
STRING |
|
Last name of the team member that sent this message. |
sent |
BOOLEAN |
|
(Posts endpoint only)If the message is sent by the requested profiles, true. Otherwise, the message is considered received by the requested profile(s) and returned false. |
post_type |
STRING |
|
Uniquely identifies the social network and type of message this is. Refer to the Post Types table for full list of valid post_types |
post_category |
STRING |
|
A unified version of post_type, these names are not network specific. |
network |
STRING |
|
The social network that the data came from (e.g. INSTAGRAM). |
perma_link |
STRING |
|
URL to the message on the social network. |
inbox_permalink |
STRING |
|
URL to the message thread in the Sprout Social Smart Inbox. Note that this field is disallowed if not when not using a group_id filter (an exception is if using message_id as a filter, but returned URL will be invalid) |
profile_guid |
STRING |
|
The ID of the profile being tracked prefixed with an Sprout code that represents where the data was collected. When the message was made by the profile being tracked, this field will be identical to from.guid. |
text |
STRING |
|
The text in the body of the message. |
title |
STRING |
|
Text that is separate from the usual body of the message, usually shown as a title for the message in the social network. |
clickthrough_link |
MAP |
|
Metadata about a link to another entity that appears on the message, e.g. when a Pinterest message contains a link to a different website. Note: For LinkedIn, only posts that have a link content type (posts that contain a link, but no photo or video) are supported. |
clickthrough_link.name |
STRING |
|
(Optional)The name given to the link as named during post time. |
clickthrough_link.long |
STRING |
|
(Optional)The full length (long) URL to the link. |
clickthrough_link.short |
STRING |
|
(Optional)The short URL of the given link, either provided at post time or generated. |
hashtags |
ARRAY<STRING> |
|
Array of hashtags associated with the message (does not include the "#" character). |
visual_media |
ARRAY<MAP> |
|
Array of media shared on the message, e.g. photos and videos. Where possible, contains URLs for the full media, a high resolution display image and a thumbnail image. |
pinterest.board_name |
STRING |
|
(Posts endpoint only)The name of the collection where users save specific pins. |
is_boosted |
BOOLEAN |
|
(Posts endpoint only)A Boolean field that indicates whether the organic posts have received paid promotion to increase reach. |
activity_metadata |
ARRAY<MAP> |
|
(Messages endpoint only)Contains information about the first of each Sprout Action(s) taken on a message, such as actor and timestamp. Depending on network limitations, this may include Reply, Tag, Complete and Like actions. |
case_id |
STRING |
|
(Messages endpoint only) Case id of the case a message is attached. |
language_code |
STRING |
|
(Messages endpoint only) ISO 639-1 language code of the message. un if unable to be determined. |
publishing_post_id |
NUMBER |
|
(Messages endpoint only) The unique identifier of the Sprout Publishing Calendar post associated with this message. Only populated for sent messages that were published via the Sprout publishing workflow. Corresponds to the publishing_post_id in the Publishing Posts endpoints. |
review_ratings |
ARRAY<MAP> |
|
(Messages endpoint only) List of review ratings, defined as a map of value to scale. |
Listening Message Fields
| Key | Type | Network Availability | Notes |
|---|---|---|---|
content_category |
STRING |
|
Unified categorization of the content. The hierarchy is album, video, photo, link, poll or text. |
created_time |
DATE |
|
An iso8601 timestamp representing the publication date and time of the message. |
from.guid |
STRING |
|
The native ID of the authors' profile prefixed with a Sprout code that represents where the data was collected. |
from.name |
STRING |
|
The display name of the author. |
from.profile_picture |
STRING |
|
URL to the profile picture. |
from.screen_name |
STRING |
|
Also commonly called "handle," this field is mutable on most networks, but not changed as often as the display name. |
from.profile_url |
STRING |


|
A url back to the author profile. |
from.followers_count |
NUMBER |
|
The latest number of followers for the profile. |
guid |
STRING |
|
The native ID of the message prefixed with a Sprout code that represents where this type of message is. |
network |
STRING |
|
The social network that the data came from (e.g. INSTAGRAM). |
perma_link |
STRING |
|
URL to the message on the social network. |
profile_guid |
STRING |
|
The ID of the profile being tracked prefixed with an Sprout code that represents where the data was collected. When the message was made by the profile being tracked, this field will be identical to from.guid. |
text |
STRING |
|
The text in the body of the message. |
title |
STRING |
|
Text that is separate from the usual body of the message, usually shown as a title for the message in the social network. |
hashtags |
ARRAY<STRING> |
|
Array of hashtags associated with the message (does not include the "#" character). |
visual_media |
ARRAY<MAP> |
|
Array of media shared on the message, e.g. photos and videos. Where possible, contains URLs for the full media, a high resolution display image and a thumbnail image. |
sentiment |
STRING |
|
The sentiment category (e.g. positive, neutral, negative, etc) of the message. |
sentiment_raw |
NUMBER |
|
A raw sentiment score between 1 and -1. Scores closer to 1 are more likely to be positive while scores closer to -1 are more likely to be negative. |
language |
STRING |
|
The primary language of the text. The primary language is selected based on which language makes up most of the text. |
location.city |
STRING |
|
An estimation of the city where the message was posted. Location data exists on X only. In some instances, we take content from the authors bio or the message itself to determine location information for other networks. |
location.province |
STRING |
|
An estimation of the province where the message was posted. Location data exists on X only. In some instances, we take content from the authors bio or the message itself to determine location information for other networks. |
location.country |
STRING |
|
An estimation of the country where the message was posted. Location data exists on X only. In some instances, we take content from the authors bio or the message itself to determine location information for other networks. |
source.name |
STRING |
|
The name of the publication or page. e.g. "The New York Times" |
source.url |
STRING |
|
The link to the publication or page. |
parent_message_id |
STRING |
|
If the message was a reply, this will hold an ID of the parent message. |
explicit_label |
STRING |
|
A true or false indication of whether the message contains explicit content. |
explicit_probability |
NUMBER |
|
A probability that the message contains explicit content. |
mentions |
ARRAY<STRING> |
|
A list of other profiles mentioned in the message. |
emoticons |
ARRAY<STRING> |
|
A list of emoticons (e.g. emoji) used in the message. |
keywords |
ARRAY<STRING> |
|
A list of keywords or phrases used in the message. |
related_words |
ARRAY<STRING> |
|
A list of related keywords used in the message. |
document.theme_ids |
ARRAY<STRING> |
|
A list of theme_ids for themes that include the message. |
Post Types
| Network | post_type value | Description |
|---|---|---|
|
|
TWEET | Post |
|
|
RETWEET | Repost |
|
|
RETWEET_COMMENT | Repost Comment |
|
|
TWITTER_DIRECT_MESSAGE | X DM |
|
|
TWITTER_FOLLOWER_ALERT | X Follower Alert |
|
|
FACEBOOK_POST | Regular FB Post (may include ‘Organic Posts’ and Dynamic Ads) |
|
|
FBCR_COMMENT | FB Comment on a Post |
|
|
FACEBOOK_AD | FB Ad Post (excluding Dynamic Ads) |
|
|
FACEBOOK_AD_COMMENT | FB Comment on an Ad Post |
|
|
FACEBOOK_MESSENGER_PM | FB Messenger Private Message |
|
|
FACEBOOK_RATING | FB Rating |
|
|
INSTAGRAM_MEDIA | IG Media |
|
|
INSTAGRAM_MEDIA_CAPTION_MENTION | IG Media Caption Mention |
|
|
INSTAGRAM_PHOTO_TAG | IG Media Tag |
|
|
INSTAGRAM_DIRECT_MESSAGE | IG DM |
|
|
INSTAGRAM_STORY | IG Story |
|
|
INSTAGRAM_STORY_MENTION | IG Story Mention |
|
|
INSTAGRAM_COMMENT_MENTION | IG Comment Mention |
|
|
INSTAGRAM_GRAPH_COMMENT | IG Comment |
|
|
FB_INSTAGRAM_AD_POST | IG Ad Post |
|
|
FB_INSTAGRAM_AD_COMMENT | IG Comment on an Ad Post |
|
|
TIKTOK_VIDEO | Tiktok Video |
|
|
TIKTOK_VIDEO_COMMENT | Tiktok comment on a Video |
|
|
TIKTOK_AD | Tiktok Ad Post |
|
|
TIKTOK_AD_COMMENT | Tiktok comment on an Ad Post |
|
|
TIKTOK_POST_MENTION | Tiktok Post Mention |
|
|
TIKTOK_COMMENT_MENTION | Tiktok Comment Mention |
|
|
PINTEREST_PIN | Pinterest Pin |
|
|
PINTEREST_REPIN | Pinterest Repin |
|
|
APPLE_APPSTORE_REVIEW | Apple App Store Review |
|
|
APPLE_APPSTORE_REVIEW_REPLY | Apple App Store Reply to Review |
|
|
BLUESKY_POST | Bluesky Post |
|
|
GOOGLE_MY_BUSINESS_REVIEW | Google My Business (GMB) Review |
|
|
GOOGLE_MY_BUSINESS_REVIEW_REPLY | Google My Business (GMB) Reply to Review |
|
|
GOOGLE_MY_BUSINESS_POST | Google My Business Public Post |
|
|
GOOGLE_PLAYSTORE_REVIEW | Google Play Store Review |
|
|
GOOGLE_PLAYSTORE_REVIEW_REPLY | Google Play Store Reply to Review |
|
|
LINKEDIN_COMPANY_COMMENT | LinkedIn Company Comment |
|
|
LINKEDIN_COMPANY_UPDATE | LinkedIn Company Update |
|
|
LINKEDIN_PERSONAL_POST | LinkedIn Personal Post |
|
|
THREADS_POST | Threads Post |
|
|
THREADS_REPLY | Threads Reply |
|
|
WHATSAPP_DIRECT_MESSAGE | Whatsapp Message |
|
|
YOUTUBE_VIDEO | Youtube Video |
|
|
YOUTUBE_COMMENT | Youtube Comment |
Topic Metrics
| Metric | Key |
|---|---|
| Total Engagement | engagements |
| Total Likes | likes |
| Total Replies | replies |
| Total Shares | shares_count |
| Author Follower Count | from.followers_count |
| Authors count | authors_count |
| Count of Positive Messages | positive_sentiments_count |
| Count of Neutral Messages | neutral_sentiments_count |
| Count of Negative Messages | negative_sentiments_count |
| Total Potential Impressions | impressions |
| Volume or Topic Messages | messages_count |
X
Note: X has additional review and compliance requirements around exposing data through the Sprout Analytics API. Customers are required to undergo a brief X review and approval process before being able to access their X data through the Sprout Analytics API. X data is not available for Listening endpoints.
X: Owned Profile Metrics
| Metric | Key | Availability |
|---|---|---|
| Followers | lifetime_snapshot.followers_count |
General Availability |
| Net Follower Growth | net_follower_growth |
General Availability |
| Impressions | impressions |
General Availability |
| Media Views | post_media_views |
Premium Analytics Required |
| Video Views | video_views |
General Availability |
| Reactions | reactions |
General Availability |
| Likes | likes |
General Availability |
| @Replies | comments_count |
General Availability |
| Reposts | shares_count |
General Availability |
| Post Clicks (All) | post_content_clicks |
General Availability |
| Post Link Clicks | post_link_clicks |
General Availability |
| Other Post Clicks | post_content_clicks_other |
General Availability |
| Post Media Clicks | post_media_clicks |
Premium Analytics Required |
| Post Hashtag Clicks | post_hashtag_clicks |
Premium Analytics Required |
| Post Detail Expand Clicks | post_detail_expand_clicks |
Premium Analytics Required |
| Profile Clicks | post_profile_clicks |
Premium Analytics Required |
| Other Engagements | engagements_other |
General Availability |
| App Engagements | post_app_engagements |
Premium Analytics Required |
| App Install Attempts | post_app_installs |
Premium Analytics Required |
| App Opens | post_app_opens |
Premium Analytics Required |
| Posts Sent Count | posts_sent_count |
General Availability |
| Posts Sent By Post Type | posts_sent_by_post_type |
General Availability |
| Posts Sent By Content Type | posts_sent_by_content_type |
General Availability |
X: Calculated Profile Metrics
The following metrics are derived from owned profile metrics:
- Followers = the last available
lifetime_snapshot.followers_countmetric - (Sprout’s default) Engagements = Likes + @Replies + Reposts + Post Link Clicks + Other Post Clicks + Other Engagements
- Engagement Rate (per Follower) = Engagements / Followers
- Engagement Rate (per Impression) = Engagements / Impressions
- Click-Through Rate = Post Link Clicks / Impressions
X: Post Metrics
| Metric | Key | Availability |
|---|---|---|
| Impressions | lifetime.impressions |
General Availability |
| Media Views | lifetime.post_media_views |
Premium Analytics Required |
| Video Views | lifetime.video_views |
General Availability |
| Reactions | lifetime.reactions |
General Availability |
| Likes | lifetime.likes |
General Availability |
| @Replies | lifetime.comments_count |
General Availability |
| Reposts | lifetime.shares_count |
General Availability |
| Post Clicks (All) | lifetime.post_content_clicks |
General Availability |
| Post Link Clicks | lifetime.post_link_clicks |
General Availability |
| Other Post Clicks | lifetime.post_content_clicks_other |
General Availability |
| Post Media Clicks | lifetime.post_media_clicks |
Premium Analytics Required |
| Post Hashtag Clicks | lifetime.post_hashtag_clicks |
Premium Analytics Required |
| Post Detail Expand Clicks | lifetime.post_detail_expand_clicks |
Premium Analytics Required |
| Profile Clicks | lifetime.post_profile_clicks |
Premium Analytics Required |
| Other Engagements | lifetime.engagements_other |
General Availability |
| Follows from Posts | lifetime.post_followers_gained |
Premium Analytics Required |
| Unfollows from Posts | lifetime.post_followers_lost |
Premium Analytics Required |
| App Engagements | lifetime.post_app_engagements |
Premium Analytics Required |
| App Install Attempts | lifetime.post_app_installs |
Premium Analytics Required |
| App Opens | lifetime.post_app_opens |
Premium Analytics Required |
| Positive Comments | lifetime.sentiment_comments_positive_count |
Premium Analytics Required |
| Negative Comments | lifetime.sentiment_comments_negative_count |
Premium Analytics Required |
| Neutral Comments | lifetime.sentiment_comments_neutral_count |
Premium Analytics Required |
| Unclassified Comments | lifetime.sentiment_comments_unclassified_count |
Premium Analytics Required |
| Net Sentiment Score | lifetime.net_sentiment_score |
Premium Analytics Required |
X: Calculated Post Metrics
The following metrics are derived from post metrics:
- (Sprout’s default) Engagements = Likes + @Replies + Reposts + Post Link Clicks + Other Post Clicks + Other Engagements
- Engagement Rate (per Follower) = Engagements / Followers
- Engagement Rate (per Impression) = Engagements / Impressions
- Click-Through Rate = Post Link Clicks / Impressions
Deprecated Metrics
On November 15, 2025, Meta deprecated several Facebook metrics related to impressions. Metrics in the below table that appear in the Sprout Metric Being Replaced column in this article will use different Facebook metrics depending on the date. For example, profile impressions will represent impressions prior to 2025. Starting January 1, 2025, profile impressions will represent views.
Facebook: Owned Profile Metrics
| Metric | Key | Availability |
|---|---|---|
| Followers | lifetime_snapshot.followers_count |
General Availability |
| Net Follower Growth | net_follower_growth |
General Availability |
| Followers Gained | followers_gained |
General Availability |
| Organic Followers Gained | followers_gained_organic |
General Availability |
| Paid Followers Gained | followers_gained_paid |
General Availability |
| Page Unlikes | followers_lost |
General Availability |
| Fans | lifetime_snapshot.fans_count |
General Availability |
| Page Likes | fans_gained |
General Availability |
| Organic Page Likes | fans_gained_organic |
General Availability |
| Paid Page Likes | fans_gained_paid |
General Availability |
| Page Unlikes | fans_lost |
General Availability |
| Impressions | impressions |
General Availability |
| Organic Impressions | impressions_organic |
General Availability |
| Viral Impressions | impressions_viral |
Premium Analytics Required |
| Non-viral Impressions | impressions_nonviral |
Premium Analytics Required |
| Paid Impressions | impressions_paid |
General Availability |
| Total Impressions | impressions_total |
General Availability |
| Page Tab Views | tab_views |
Premium Analytics Required |
| Logged In Page Tab Views | tab_views_login |
Premium Analytics Required |
| Logged Out Page Tab Views | tab_views_logout |
Premium Analytics Required |
| Organic Post Impressions | post_impressions_organic |
Premium Analytics Required |
| Reach | impressions_unique |
General Availability |
| Organic Reach | impressions_organic_unique |
General Availability |
| Reactions | reactions |
General Availability |
| Comments | comments_count |
General Availability |
| Shares | shares_count |
General Availability |
| Post Link Clicks | post_link_clicks |
General Availability |
| Other Post Clicks | post_content_clicks_other |
General Availability |
| Page Actions | profile_actions |
General Availability |
| Post Engagements | post_engagements |
Premium Analytics Required |
| Video Views | video_views |
General Availability |
| Organic Video Views | video_views_organic |
General Availability |
| Paid Video Views | video_views_paid |
General Availability |
| Autoplay Video Views | video_views_autoplay |
Premium Analytics Required |
| Click to Play Video Views | video_views_click_to_play |
Premium Analytics Required |
| Replayed Video Views | video_views_repeat |
Premium Analytics Required |
| Video View Time | video_view_time |
Premium Analytics Required |
| Full Video Views | video_views_30s_complete |
Premium Analytics Required |
| Organic Full Video Views | video_views_30s_complete_organic |
Premium Analytics Required |
| Paid Full Video Views | video_views_30s_complete_paid |
Premium Analytics Required |
| Autoplay Full Video Views | video_views_30s_complete_autoplay |
Premium Analytics Required |
| Click to Play Full Video Views | video_views_30s_complete_click_to_play |
Premium Analytics Required |
| Replayed Full Video Views | video_views_30s_complete_repeat |
Premium Analytics Required |
| Unique Full Video Views | video_views_30s_complete_unique |
Premium Analytics Required |
| Partial Video Views | video_views_partial |
Premium Analytics Required |
| Organic Partial Video Views | video_views_partial_organic |
Premium Analytics Required |
| Paid Partial Video Views | video_views_partial_paid |
Premium Analytics Required |
| Autoplay Partial Video Views | video_views_partial_autoplay |
Premium Analytics Required |
| Click to Play Partial Video Views | video_views_partial_click_to_play |
Premium Analytics Required |
| Replayed Partial Video Views | video_views_partial_repeat |
Premium Analytics Required |
| Posts Sent Count | posts_sent_count |
General Availability |
| Posts Sent By Post Type | posts_sent_by_post_type |
General Availability |
| Posts Sent By Content Type | posts_sent_by_content_type |
General Availability |
Facebook: Calculated Profile Metrics
The following metrics are derived from owned profile metrics:
- Fans = the last available
lifetime_snapshot.followers_countmetric - (Sprout’s default) Engagements = Reactions + Comments + Shares + Post Link Clicks + Other Post Clicks
- Engagement Rate (per Follower) = Engagements / Followers
- Engagement Rate (per Impression) = Engagements / Impressions
- Click-Through Rate = Post Link Clicks / Impressions
Facebook: Post Metrics
Deprecated Metrics
On November 15, 2025, Meta deprecated several Facebook metrics related to impressions. Metrics in the below table that appear in the Sprout Metric Being Replaced column in this article will use different Facebook metrics depending on the date. For example, post impressions will represent impressions prior to 2025. Starting January 1, 2025, post impressions will represent views.
| Metric | Key | Availability |
|---|---|---|
| Impressions | lifetime.impressions |
General Availability |
| Organic Impressions | lifetime.impressions_organic |
General Availability |
| Viral Impressions | lifetime.impressions_viral |
Premium Analytics Required |
| Non-viral Impressions | lifetime.impressions_nonviral |
Premium Analytics Required |
| Paid Impressions | lifetime.impressions_paid |
General Availability |
| Fan Impressions | lifetime.impressions_follower |
Premium Analytics Required |
| Non-fan Impressions | lifetime.impressions_nonfollower |
Premium Analytics Required |
| Reach | lifetime.impressions_unique |
General Availability |
| Fan Reach | lifetime.impressions_follower_unique |
Premium Analytics Required |
| Reactions | lifetime.reactions |
General Availability |
| Likes | lifetime.likes |
General Availability |
| Love Reactions | lifetime.reactions_love |
General Availability |
| Haha Reactions | lifetime.reactions_haha |
General Availability |
| Wow Reactions | lifetime.reactions_wow |
General Availability |
| Sad Reactions | lifetime.reactions_sad |
General Availability |
| Angry Reactions | lifetime.reactions_angry |
General Availability |
| Comments | lifetime.comments_count |
General Availability |
| Shares | lifetime.shares_count |
General Availability |
| Post Shares | lifetime.post_shares_count |
General Availability |
| Answers | lifetime.question_answers |
Premium Analytics Required |
| Post Clicks (All) | lifetime.post_content_clicks |
General Availability |
| Post Link Clicks | lifetime.post_link_clicks |
General Availability |
| Post Photo View Clicks | lifetime.post_photo_view_clicks |
General Availability |
| Post Video Play Clicks | lifetime.post_video_play_clicks |
General Availability |
| Other Post Clicks | lifetime.post_content_clicks_other |
General Availability |
| Video Length | video_length |
Premium Analytics Required |
| Video Views | lifetime.video_views |
General Availability |
| Organic Video Views | lifetime.video_views_organic |
General Availability |
| Paid Video Views | lifetime.video_views_paid |
General Availability |
| Autoplay Video Views | lifetime.video_views_autoplay |
Premium Analytics Required |
| Click to Play Video Views | lifetime.video_views_click_to_play |
Premium Analytics Required |
| Sound on Video Views | lifetime.video_views_sound_on |
Premium Analytics Required |
| Sound off Video Views | lifetime.video_views_sound_off |
Premium Analytics Required |
| Partial Video Views | lifetime.video_views_partial |
Premium Analytics Required |
| Organic Partial Video Views | lifetime.video_views_partial_organic |
Premium Analytics Required |
| Paid Partial Video Views | lifetime.video_views_partial_paid |
Premium Analytics Required |
| Autoplay Partial Video Views | lifetime.video_views_partial_autoplay |
Premium Analytics Required |
| Click to Play Partial Video Views | lifetime.video_views_partial_click_to_play |
Premium Analytics Required |
| Full Video Views | lifetime.video_views_30s_complete |
Premium Analytics Required |
| Organic Full Video Views | lifetime.video_views_30s_complete_organic |
Premium Analytics Required |
| Paid Full Video Views | lifetime.video_views_30s_complete_paid |
Premium Analytics Required |
| Autoplay Full Video Views | lifetime.video_views_30s_complete_autoplay |
Premium Analytics Required |
| Click to Play Full Video Views | lifetime.video_views_30s_complete_click_to_play |
Premium Analytics Required |
| 95% Video Views | lifetime.video_views_p95 |
Premium Analytics Required |
| Organic 95% Video Views | lifetime.video_views_p95_organic |
Premium Analytics Required |
| Paid 95% Video Views | lifetime.video_views_p95_paid |
Premium Analytics Required |
| Reels Unique Session Plays | lifetime.reels_unique_session_plays |
General Availability |
| Unique Full Video Views | lifetime.video_views_30s_complete_unique |
Premium Analytics Required |
| Unique Organic 95% Video Views | lifetime.video_views_p95_organic_unique |
Premium Analytics Required |
| Unique Paid 95% Video Views | lifetime.video_views_p95_paid_unique |
Premium Analytics Required |
| Average Video Time Watched | lifetime.video_view_time_per_view |
Premium Analytics Required |
| Video View Time | lifetime.video_view_time |
Premium Analytics Required |
| Organic Video View Time | lifetime.video_view_time_organic |
Premium Analytics Required |
| Paid Video View Time | lifetime.video_view_time_paid |
Premium Analytics Required |
| Video Ad Break Ad Impressions | lifetime.video_ad_break_impressions |
Premium Analytics Required |
| Video Ad Break Ad Earnings | lifetime.video_ad_break_earnings |
Premium Analytics Required |
| Video Ad Break Ad Cost per Impression (CPM) | lifetime.video_ad_break_cost_per_impression |
Premium Analytics Required |
| Positive Comments | lifetime.sentiment_comments_positive_count |
Premium Analytics Required |
| Negative Comments | lifetime.sentiment_comments_negative_count |
Premium Analytics Required |
| Neutral Comments | lifetime.sentiment_comments_neutral_count |
Premium Analytics Required |
| Unclassified Comments | lifetime.sentiment_comments_unclassified_count |
Premium Analytics Required |
| Net Sentiment Score | lifetime.net_sentiment_score |
Premium Analytics Required |
Facebook: Calculated Post Metrics
The following metrics are derived from post metrics:
- (Sprout’s default) Engagements = Reactions + Comments + Shares + Post Link Clicks + Other Post Clicks
- Engagement Rate (per Follower) = Engagements / Followers
- Engagement Rate (per Impression) = Engagements / Impressions
- Engagement Rate (per Reach) = Engagements / Reach
- Click-Through Rate = Post Link Clicks / Impressions
Instagram: Owned Profile Metrics
| Metric | Key | Availability |
|---|---|---|
| Followers | lifetime_snapshot.followers_count |
General Availability |
| Followers By Age Gender | lifetime_snapshot.followers_by_age_gender |
General Availability |
| Followers By City | lifetime_snapshot.followers_by_city |
General Availability |
| Followers By Country | lifetime_snapshot.followers_by_country |
General Availability |
| Net Follower Growth | net_follower_growth |
General Availability |
| Followers Gained | followers_gained |
General Availability |
| Followers Lost | followers_lost |
General Availability |
| Following | lifetime_snapshot.following_count |
General Availability |
| Net Following Growth | net_following_growth |
General Availability |
| Views | impressions |
General Availability |
| Paid Views | impressions_paid |
General Availability |
| Organic Views | impressions_organic |
General Availability |
| Total Views | impressions_total |
General Availability |
| Reach | impressions_unique |
General Availability |
| Post Video Views | video_views |
General Availability |
| Reactions | reactions |
General Availability |
| Likes | likes |
General Availability |
| Comments | comments_count |
General Availability |
| Saves | saves |
General Availability |
| Shares | shares_count |
General Availability |
| Story Replies | story_replies |
General Availability |
| Posts Sent Count | posts_sent_count |
General Availability |
| Posts Sent By Post Type | posts_sent_by_post_type |
General Availability |
| Posts Sent By Content Type | posts_sent_by_content_type |
General Availability |
| Total Views | views |
General Availability |
Instagram: Calculated Profile Metrics
The following metrics are derived from owned profile metrics:
- Followers = the last available
lifetime_snapshot.followers_countmetric - (Sprout’s default) Engagements = Likes + Comments + Shares + Saves + Story Replies
- Engagement Rate (per Follower) = Engagements / Followers
- Engagement Rate (per Impression) = Engagements / Impressions
Instagram: Post Metrics
| Metric | Key | Availability |
|---|---|---|
| Comments | lifetime.comments_count |
General Availability |
| Impressions | lifetime.impressions |
General Availability |
| Likes | lifetime.likes |
General Availability |
| Reach | lifetime.impressions_unique |
General Availability |
| Reactions | lifetime.reactions |
General Availability |
| Reels Unique Session Plays | lifetime.reels_unique_session_plays |
General Availability |
| Saves | lifetime.saves |
General Availability |
| Shares | lifetime.shares_count |
General Availability |
| Post Shares | lifetime.post_shares_count |
General Availability |
| SproutLink Clicks | lifetime.link_in_bio_clicks |
General Availability |
| Story Exits | lifetime.story_exits |
General Availability |
| Story Replies | lifetime.comments_count |
General Availability |
| Story Taps Back | lifetime.story_taps_back |
General Availability |
| Story Taps Forward | lifetime.story_taps_forward |
General Availability |
| Video View Time | lifetime.video_view_time |
General Availability |
| Average Video Time Watched | lifetime.video_view_time_per_view |
General Availability |
| Video Views | lifetime.video_views |
General Availability |
| Views | lifetime.views |
General Availability |
| Positive Comments | lifetime.sentiment_comments_positive_count |
Premium Analytics Required |
| Negative Comments | lifetime.sentiment_comments_negative_count |
Premium Analytics Required |
| Neutral Comments | lifetime.sentiment_comments_neutral_count |
Premium Analytics Required |
| Unclassified Comments | lifetime.sentiment_comments_unclassified_count |
Premium Analytics Required |
| Net Sentiment Score | lifetime.net_sentiment_score |
Premium Analytics Required |
Instagram: Calculated Post Metrics
The following metrics are derived from post metrics:
- (Sprout’s default) Engagements = Likes + Comments + Shares + Saves + Story Replies
- Engagement Rate (per Follower) = Engagements / Followers
- Engagement Rate (per Impression) = Engagements / Impressions
- Engagement Rate (per Reach) = Engagements / Reach
- Click-Through Rate = Post Link Clicks / Impressions
LinkedIn: Owned Profile Metrics
| Metric | Key | Availability |
|---|---|---|
| Followers | lifetime_snapshot.followers_count |
General Availability |
| Followers By Job | followers_by_job_function |
General Availability |
| Followers By Seniority | followers_by_seniority |
General Availability |
| Net Follower Growth | net_follower_growth |
General Availability |
| Followers Gained | followers_gained |
General Availability |
| Organic Followers Gained | followers_gained_organic |
General Availability |
| Paid Followers Gained | followers_gained_paid |
General Availability |
| Followers Lost | followers_lost |
General Availability |
| Impressions | impressions |
General Availability |
| Reach | impressions_unique |
General Availability |
| Reactions | reactions |
General Availability |
| Comments | comments_count |
General Availability |
| Shares | shares_count |
General Availability |
| Post Clicks (All) | post_content_clicks |
General Availability |
| Posts Sent Count | posts_sent_count |
General Availability |
| Posts Sent By Post Type | posts_sent_by_post_type |
General Availability |
| Posts Sent By Content Type | posts_sent_by_content_type |
General Availability |
LinkedIn: Calculated Profile Metrics
The following metrics are derived from owned profile metrics:
- Followers = the last available
lifetime_snapshot.followers_countmetric - (Sprout’s default) Engagements = Reactions + Comments + Shares + Post Clicks (All)
- Engagement Rate (per Follower) = Engagements / Followers
- Engagement Rate (per Impression) = Engagements / Impressions
LinkedIn: Post Metrics
| Metric | Key | Availability |
|---|---|---|
| Impressions | lifetime.impressions |
General Availability |
| Unique Impressions | lifetime.impressions_unique |
General Availability |
| Reactions | lifetime.reactions |
General Availability |
| Comments | lifetime.comments_count |
General Availability |
| Shares | lifetime.shares_count |
General Availability |
| Post Shares | lifetime.post_shares_count |
General Availability |
| Post Clicks (All) | lifetime.post_content_clicks |
General Availability |
| Video Views | lifetime.video_views |
General Availability |
| Unique Video Views | lifetime.video_views_unique |
General Availability |
| Video View Time | lifetime.video_view_time |
General Availability |
| Poll Votes | lifetime.vote_count |
General Availability |
| Positive Comments | lifetime.sentiment_comments_positive_count |
Premium Analytics Required |
| Negative Comments | lifetime.sentiment_comments_negative_count |
Premium Analytics Required |
| Neutral Comments | lifetime.sentiment_comments_neutral_count |
Premium Analytics Required |
| Unclassified Comments | lifetime.sentiment_comments_unclassified_count |
Premium Analytics Required |
| Net Sentiment Score | lifetime.net_sentiment_score |
Premium Analytics Required |
LinkedIn: Calculated Post Metrics
The following metrics are derived from post metrics:
- (Sprout’s default) Engagements = Reactions + Comments + Shares + Post Clicks (All)
- Engagement Rate (per Follower) = Engagements / Followers
- Engagement Rate (per Impression) = Engagements / Impressions
- Engagement Rate (per Reach) = Engagements / Reach
YouTube
YouTube: Owned Profile Metrics
| Metric | Key | Availability |
|---|---|---|
| Followers | lifetime_snapshot.followers_count |
General Availability |
| Net Follower Growth | net_follower_growth |
General Availability |
| Followers Gained | followers_gained |
General Availability |
| Followers Lost | followers_lost |
General Availability |
| Posts Sent Count | posts_sent_count |
General Availability |
YouTube: Calculated Profile Metrics
The following metrics are derived from owned profile metrics:
- Net Follower Growth = Followers Gained - Followers Lost
- (Sprout’s default) Video Engagements = Comments + Likes + Dislikes + Shares + Subscribers Gained + Annotation Clicks + Card Clicks
- (Sprout’s default) Video Engagements Per View = Video Engagements / Video Views
YouTube: Post Metrics
| Metric | Key | Availability |
|---|---|---|
| Annotation Clicks | lifetime.annotation_clicks |
Premium Analytics Required |
| Annotation Click Rate | lifetime.annotation_click_through_rate |
Premium Analytics Required |
| Clickable Annotation Impressions | lifetime.annotation_clickable_impressions |
Premium Analytics Required |
| Closable Annotation Impressions | lifetime.annotation_closable_impressions |
Premium Analytics Required |
| Annotation Closes | lifetime.annotation_closes |
Premium Analytics Required |
| Annotation Close Rate | lifetime.annotation_close_rate |
Premium Analytics Required |
| Annotation Impressions | lifetime.annotation_impressions |
Premium Analytics Required |
| Card Clicks | lifetime.card_clicks |
Premium Analytics Required |
| Card Impressions | lifetime.card_impressions |
Premium Analytics Required |
| Card Click Rate | lifetime.card_click_rate |
Premium Analytics Required |
| Card Teaser Clicks | lifetime.card_teaser_clicks |
Premium Analytics Required |
| Card Teaser Impressions | lifetime.card_teaser_impressions |
Premium Analytics Required |
| Card Teaser Click Rate | lifetime.card_teaser_click_rate |
Premium Analytics Required |
| Estimated Minutes Watched | lifetime.estimated_minutes_watched |
General Availability |
| Estimated YT Red Minutes Watched | lifetime.estimated_red_minutes_watched |
Premium Analytics Required |
| Content Click Other | lifetime.post_content_clicks_other |
Premium Analytics Required |
| Shares | lifetime.shares_count |
General Availability |
| Post Shares | lifetime.post_shares_count |
General Availability |
| Subscribers Gained | lifetime.subscribers_gained |
General Availability |
| Subscribers Lost | lifetime.subscribers_lost |
General Availability |
| YT Red Video Views | lifetime.red_video_views |
Premium Analytics Required |
| Video Views | lifetime.video_views |
General Availability |
| Video Likes | lifetime.likes |
General Availability |
| Video Dislikes | lifetime.dislikes |
General Availability |
| Video Reactions | lifetime.reactions |
General Availability |
| Video Comments | lifetime.comments_count |
General Availability |
| Video Added to Playlist | lifetime.videos_added_to_playlist |
Premium Analytics Required |
| Video From to Playlist | lifetime.videos_removed_from_playlist |
Premium Analytics Required |
| Positive Comments | lifetime.sentiment_comments_positive_count |
Premium Analytics Required |
| Negative Comments | lifetime.sentiment_comments_negative_count |
Premium Analytics Required |
| Neutral Comments | lifetime.sentiment_comments_neutral_count |
Premium Analytics Required |
| Unclassified Comments | lifetime.sentiment_comments_unclassified_count |
Premium Analytics Required |
| Net Sentiment Score | lifetime.net_sentiment_score |
Premium Analytics Required |
YouTube: Calculated Post Metrics
The following metrics are derived from post metrics:
- Content Click Other = Annotation Clicks + Card Clicks
- Video Reactions = Likes + Dislikes
- (Sprout’s default) Video Engagements = Comments + Likes + Dislikes + Shares + Subscribers Gained + Annotation Clicks + Card Clicks
- (Sprout’s default) Video Engagements Per View = Video Engagements/Video Views
Pinterest: Owned Profile Metrics
| Metric | Key | Availability |
|---|---|---|
| Followers Count | lifetime_snapshot.followers_count |
General Availability |
| Following Count | lifetime_snapshot.following_count |
General Availability |
| Followers Gained | followers_gained |
General Availability |
| Followers Lost | followers_lost |
General Availability |
| Net Follower Growth | net_follower_growth |
General Availability |
| Net Following Growth | net_following_growth |
General Availability |
| Pin Count | pin_count |
General Availability |
| Pin Sent | inbox_counts_sent |
General Availability |
| Pin Received | inbox_received_sent |
General Availability |
Pinterest: Calculated Post Metrics
The following metrics are derived from owned profile metrics:
- Net Follower Growth = Followers Gained - Followers Lost
Pinterest: Post Metrics
| Metric | Key | Availability |
|---|---|---|
| Comments | lifetime.comments_count |
General Availability |
| Pin Saves | lifetime.saves |
General Availability |
Threads
Threads: Owned Profile Metrics
| Metric | Key | Availability |
|---|---|---|
| Followers By Age Gender | lifetime_snapshot.followers_by_age_gender |
General Availability |
| Followers By City | lifetime_snapshot.followers_by_city |
General Availability |
| Followers By Country | lifetime_snapshot.followers_by_country |
General Availability |
| Likes | likes |
General Availability |
| Profile Views | profile_views |
General Availability |
| Quotes | quotes_count |
General Availability |
| Replies | comments_count |
General Availability |
| Reposts | reposts_count |
General Availability |
| Shares | shares_count |
General Availability |
Threads: Calculated Profile Metrics
The following metrics are derived from owned profile metrics:
- Shares = Reposts + Quotes
- (Sprout’s default) Engagements = Likes + Replies + Shares
Threads: Post Metrics
| Metric | Key | Availability |
|---|---|---|
| Replies | lifetime.comments_count |
General Availability |
| Impressions | lifetime.impressions |
General Availability |
| Likes | lifetime.likes |
General Availability |
| Reactions | lifetime.reactions |
General Availability |
| Shares | lifetime.shares_count |
General Availability |
| Post Shares | lifetime.post_shares_count |
General Availability |
| Positive Comments | lifetime.sentiment_comments_positive_count |
Premium Analytics Required |
| Negative Comments | lifetime.sentiment_comments_negative_count |
Premium Analytics Required |
| Neutral Comments | lifetime.sentiment_comments_neutral_count |
Premium Analytics Required |
| Unclassified Comments | lifetime.sentiment_comments_unclassified_count |
Premium Analytics Required |
| Net Sentiment Score | lifetime.net_sentiment_score |
Premium Analytics Required |
Threads: Calculated Post Metrics
The following metrics are derived from post metrics:
- (Sprout’s default) Engagements = Reactions + Comments + Shares
- Engagement Rate (per Impression) = Engagements / Impressions
TikTok
TikTok: Owned Profile Metrics
| Metric | Key | Availability |
|---|---|---|
| Comments | comments_count_total |
General Availability |
| Followers By Country | lifetime_snapshot.followers_by_country |
General Availability |
| Followers By Gender | lifetime_snapshot.followers_by_gender |
General Availability |
| Followers Count | lifetime_snapshot.followers_count |
General Availability |
| Followers Online | lifetime_snapshot.followers_online |
General Availability |
| Likes | likes_total |
General Availability |
| Net Follower Growth | net_follower_growth |
General Availability |
| Published Posts by Post Type | posts_sent_by_post_type |
General Availability |
| Published Post | posts_sent_count |
General Availability |
| Profiles Views | profile_views_total |
General Availability |
| Shares | shares_count_total |
General Availability |
| Video Views | video_views_total |
General Availability |
TikTok: Calculated Profile Metrics
The following metrics are derived from owned profile metrics:
- (Sprout’s default) Engagements = Likes + Comments + Shares
- Engagement Rate (per Impression) = Engagements / Impressions
TikTok: Post Metrics
| Metric | Key | Availability |
|---|---|---|
| Average Video Time Watched | lifetime.video_view_time_per_view |
General Availability |
| Comments | lifetime.comments_count |
General Availability |
| Full Video Watch Rate | lifetime.video_views_p100_per_view |
General Availability |
| Impression Source Follow | lifetime.impression_source_follow |
General Availability |
| Impression Source For You | lifetime.impression_source_for_you |
General Availability |
| Impression Source Hashtag | lifetime.impression_source_hashtag |
General Availability |
| Impression Source Personal Profile | lifetime.impression_source_personal_profile |
General Availability |
| Impression Source Sound | lifetime.impression_source_sound |
General Availability |
| Impression Source Unspecified | lifetime.impression_source_unspecified |
General Availability |
| Likes | lifetime.likes |
General Availability |
| Reach | lifetime.impressions_unique |
General Availability |
| Reactions | lifetime.reactions |
General Availability |
| Shares | lifetime.shares_count |
General Availability |
| Post Shares | lifetime.post_shares_count |
General Availability |
| Video Length | video_length |
Premium Analytics Required |
| Video View Time | lifetime.video_view_time |
Premium Analytics Required |
| Video Views | lifetime.video_views |
General Availability |
| Positive Comments | lifetime.sentiment_comments_positive_count |
Premium Analytics Required |
| Negative Comments | lifetime.sentiment_comments_negative_count |
Premium Analytics Required |
| Neutral Comments | lifetime.sentiment_comments_neutral_count |
Premium Analytics Required |
| Unclassified Comments | lifetime.sentiment_comments_unclassified_count |
Premium Analytics Required |
| Net Sentiment Score | lifetime.net_sentiment_score |
Premium Analytics Required |
TikTok: Calculated Post Metrics
The following metrics are derived from owned post metrics:
- (Sprout’s default) Engagements = Likes + Comments + Shares
- Engagement Rate (per Impression) = Engagements / Impressions
Bluesky
Bluesky: Post Metrics
| Metric | Key | Availability |
|---|---|---|
| Replies | lifetime.comments_count |
General Availability |
| Likes | lifetime.likes |
General Availability |
| Quotes | lifetime.quotes_count |
General Availability |
| Reactions | lifetime.reactions |
General Availability |
| Reposts | lifetime.reposts_count |
General Availability |
| Shares | lifetime.shares_count |
General Availability |
Bluesky: Calculated Post Metrics
The following metrics are derived from post metrics:
- Shares = Reposts + Quotes
- (Sprout’s default) Engagements = Replies + Reactions + Shares
Sprout Tableau Connector
Available Data Overview
✅ The Tableau Connector uses the Sprout API to bring social data into Tableau. The metrics and data points pull directly from those available in the Sprout API. Of the data available via the Sprout API data, these tables are directly available in Tableau:
- ✅ Owned Profile Data - This matches the data available in Sprout’s Profile Performance, X Profiles, Facebook Pages, Instagram Business Profiles, LinkedIn Pages, Pinterest Profiles, TikTok Profiles and YouTube Videos Report.
- ✅ Post Data - This matches the data available in Sprout’s Post Performance Report.
- ✅ Tag Data - This matches the tags represented in Sprout’s Tag Performance Report. Tag data can be combined with Post Data to fully analyze tagged posts.
🚫 The Sprout Tableau Connector does not currently include:
- 🚫 Messages data
- 🚫 Data Unsupported in Sprout API. For more details reference the Available Data Overview section of this doc.
Access Requirements
In order to access the Sprout Tableau Connector users must:
- Have access to the Sprout API and a valid API Key. For more details reference the Creating an Access Token section of this doc
- Have access to Tableau
Connection Set Up
-
Open Tableau
-
Select Data > New Data Source
-
Select a Web Data Connector
-
Input Connector URL https://api.sproutsocial.com/tableau/

-
Paste in API Key, Chose Date Range, and Select "Connect".
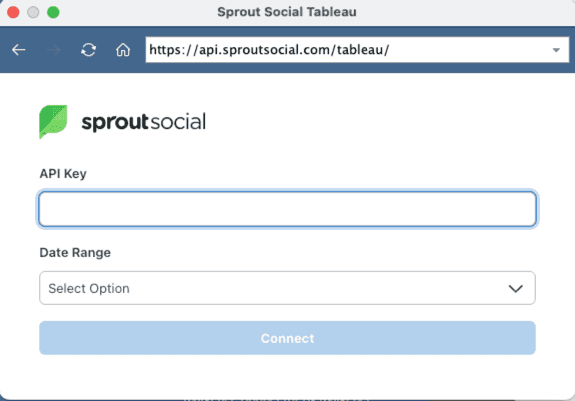
-
Select a Standard Connection (Post, Profile, Tag) or individual data tables
*Note that the Tableau connector does not support IPv6. Please use IPv4, or enable IPv6<->IPv4 translation.